
Photo by author
# Introduction
For decades, artificial intelligence (AI) meant text. You typed a question, got a text answer. Even as language models became more capable, the interface remained the same: a text box awaiting your carefully crafted gestures.
This is changing. Today’s most capable AI systems don’t just read. They see images, listen to speech, process video and understand structured data. This is not incremental progress. This is a fundamental change in how we interact with and work with AI applications.
Welcome to Multimodal AI.
The real impact isn’t just that models can process more types of data. This is where entire workflows are falling apart. Tasks that require multiple conversion steps at once. AI understands information in its native form, eliminating the translation layer that has defined human-computer interaction for decades.
# Defining Multimodal Artificial Intelligence: From Single-Sense to Multi-Sense Intelligence
Multimodal AI refers to systems that can process and generate multiple types of data (modalities) simultaneously. This includes not only text, but also images, audio, video, and increasingly, 3D spatial data, structural databases, and domain-specific formats such as molecular structures or musical notation.
Progress wasn’t just making models bigger. It was learning to represent different types of data in a shared “understanding space” where they could interact. An image and its title are not separate things that are associated with it. They are different expressions of the same basic concept, mapped onto a common representation.
This creates capabilities that single modality systems cannot achieve. Only a text AI can describe an image if you describe it in words. A multimodal AI can look at an image and understand context you never mentioned: lighting, emotions on faces, spatial relationships between objects. It simply does not process multiple inputs. It inculcates understanding in them.
Distinguish between “truly multimodal” models and “multimodal system” cases. Some models implement everything together in a unified architecture. GPT-4 Vision (GPT-4V) Sees and understands at the same time. Others integrate specialized models: a vision model analyzes an image, then passes the results to a language model for reasoning. Both approaches work. The former offers tighter integration, while the latter offers greater flexibility and specialization.
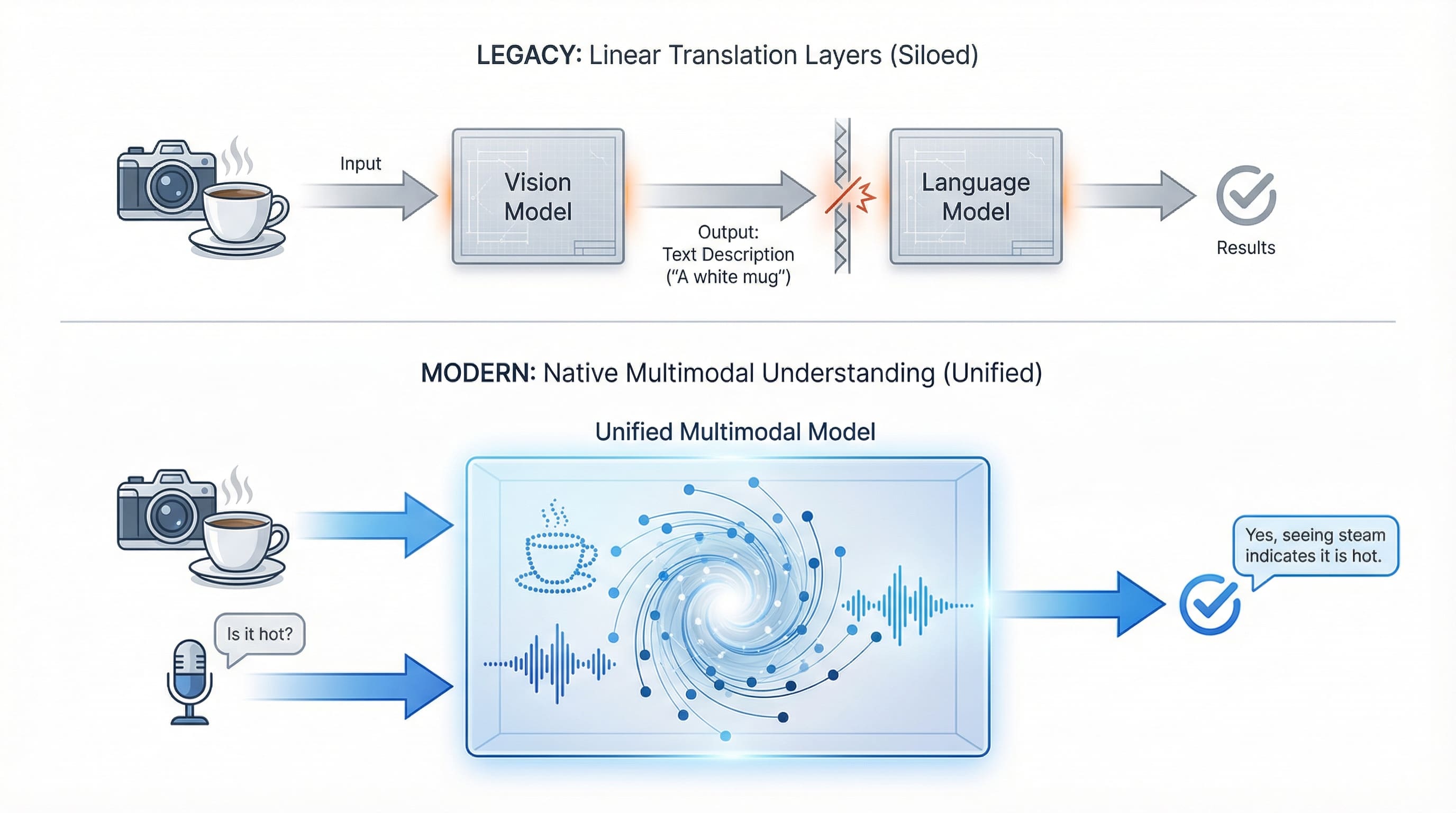
Legacy systems require translation between specialized models, whereas modern multimodal AI processes vision and voice simultaneously in a unified architecture. | Photo by author
# Understanding the foundational trio: vision, sound, and text models
Three approaches have matured enough for widespread production use, each bringing distinct capabilities and distinct engineering constraints to AI systems.
// Advancing visual understanding
Vision AI has evolved from basic image classification to true visual understanding. GPT-4V and Claude Can analyze debug code from charts, screenshots, and understand complex visual contexts. Gemini Integrates vision natively throughout its interface. Open source alternative- Lavafor , for , for , . Qwen-Vland cogvlm – Rival trading options in many tasks now running on consumer hardware.
This is where the workflow shift becomes apparent: Instead of describing what you see in a screenshot or manually copying chart data, you simply display it. AI sees it directly. What used to take five minutes of careful detailing now takes five seconds to upload.
Engineering reality, however, imposes constraints. You usually can’t stream RAW 60fps video in a large language model (LLM). It is very slow and expensive. Use production systems Frame Samplingextracting keyframes (perhaps one every two seconds) or deploying lightweight “change detection” models to only send frames when the visual scene changes.
What enables vision is not just recognition of objects. This is spatial reasoning: realizing that the cup is on the table, not floating. This is reading implicit information: recognizing that a cluttered desk suggests tension, or that the trend of a graph contradicts the accompanying text. Vision AI improves document analysis, visual debugging, image generation, and any task where “show, don’t tell” applies.
// Ready voice and audio interaction
Voice AI goes beyond simple transcription. The whisper Transformed the field by making high-quality speech recognition independent and localized. It handles accents, background noise, and multilingual audio with remarkable reliability. But Voice AI is now included through Text-to-Speech (TTS). Eleven lobesfor , for , for , . The barkor Cookiewith emotion detection and speaker recognition.
Voice breaks down another conversion barrier: you speak naturally instead of typing what you want to say. AI listens to your tone, picks up on your hesitation, and responds to what you mean, not just the words you’ve managed to type.
Frontier Challenge is not a transcription standard. This is delay and turn taking. In a real-time conversation, waiting three seconds for a response feels unnatural. Engineers deal with it Voice Activity Detection (VAD)algorithms that detect the precise millisecond that a user stops talking to immediately trigger the model, and additionally “seed in” help that interrupts the user mid-reaction to the AI.
Difference between copying and understanding cases. Whisper converts speech to text with impressive accuracy. However, new voice models capture tone, detect sarcasm, identify hesitation, and understand context that text alone misses. A customer saying “OK” with frustration is different from “OK” with satisfaction. Voice AI captures this distinction.
// Synthesizing with text integration
Text integration acts as the glue that binds everything together. Language models provide reasoning, synthesis, and generation capabilities that other methods lack. A vision model can identify objects in an image. An LLM explains their importance. An audio model can simulate speech. An LLM draws insights from conversation.
Capacity comes from combination. Show an AI a medical scan describing the symptoms, and it synthesizes the understanding into methods. This goes beyond parallel processing. This is true polynomial reasoning where each situation informs the interpretation of the others.
# Exploring emerging frontiers beyond the basics
While vision, voice and text dominate current applications, the multimodal landscape is expanding rapidly.
3D and spatial understanding Moves AI beyond flat images into physical space. Models that capture depth, three-dimensional relationships, and spatial reasoning enable tools for robotics, augmented reality (AR), virtual reality (VR) applications, and architecture. These systems assume that the chair viewed from different angles is the same object.
Structural data As such a situation represents a subtle but significant evolution. Instead of converting spreadsheets to text for LLMS, new systems understand tables, databases, and graphs natively. They recognize that a column represents a category, relationships between tables have meaning, and that time series data contain temporal patterns. This allows AI to query databases directly, without prompts, to analyze financial statements and to reason about structured information without harmful conversions to text.
When AI understands spatial forms, entirely new capabilities emerge. A financial analyst might point to a spreadsheet and ask, “Why did revenues fall in Q3?” AI reads the table structure, spots the anomaly, and explains it. An architect can feed in 3D models and get spatial feedback without converting everything to a 2D diagram first.
Domain specific methods Target specific fields. AlfalfaThe ability to understand the structure of proteins led to drug discovery for AI. Models that understand musical notation enable composition tools. Systems that process sensor data and time series information bring AI to the Internet of Things (IoT) and industrial monitoring.
# Implementing real-world applications
Multimodal AI has moved from research papers to production systems solving real problems.
- Content analysis: Video platforms use vision to detect scenes, audio to simulate dialogue, and text models to summarize content. Medical imaging systems combine visual analysis of scans with patient history and symptom description to aid diagnosis.
- Accessible tools: Real-time sign language translation combines vision (looking at gestures) with a language model (generating text or speech). Image description services help visually impaired users understand visual content.
- Creative workflows: Designers are sketch interfaces that convert to AI code by verbally explaining design decisions. Content creators explain concepts in speech while AI generates matching visuals.
- Developer Tools: Debugging assistants watch your screen, read error messages, and verbally explain solutions. Code review tools analyze both the structure of the code and its associated diagrams or documentation.
The change is reflected in how people work: instead of switching contexts between tools, you just show and ask. Friction disappears. A multimodal approach allows each information type to remain in its native form.
The challenge in production is often less about capacity and more about latency. A voice-to-voice system has to process audio in under 500ms to make audio → text → reasoning → text → audio feel natural, which requires a streaming architecture that processes the data in chunks.
# Navigating the Emerging Multimodal Infrastructure
A new infrastructure layer is building around multimodal development:
- Model providers: Openai, Anthropic, and Google led commercial offerings. Democratizing access to open source projects such as the Lalava family and Quen-vl.
- Framework support: Lingchen Add multimodal chains to process mixed media workflows. llamaindex Extends Regenerative Generation (RAG) samples from recovery to images and audio.
- Specialized providers: Eleven Labs dominates voice synthesis, while Midjourney And Stability AI Lead image generation.
- Integration Protocol: Model Context Protocol (MCP) Standardizing how AI systems connect to multimodal data sources.
The infrastructure is to democratize multimodal AI. What required research teams years ago now runs in framework code. Thousands in API fees now run natively on customers’ hardware.
# Summarizing the key path
Multimodal AI represents more than technical capability. It is changing how humans and computers interact. Graphical user interfaces (GUIs) are giving way to multimodal interfaces where you naturally show, tell, draw, and speak.
It enables new patterns of interaction Visual grounding. “What’s that red thing in the corner?” Instead of typing, users simply draw a circle on their screen and ask “What’s this?” The AI receives both image coordinates and text, anchoring language to visual pixels.
The future of AI isn’t choosing between vision, voice, or text. It is the building system that treats all three as naturally human beings.
Vinod Chogani is an AI and data science educator who bridges the gap between emerging AI technologies and practical applications for working professionals. His focus areas include agentic AI, machine learning applications, and automation workflows. Through his work as a technical mentor and instructor, Vinod has supported data professionals through skill development and career transition. He brings analytical expertise from quantitative finance to his hands-on teaching approach. Its content emphasizes actionable strategies and frameworks that professionals can apply immediately.