


Photo by the author Canva
# Introduction
Data analysis problems are not really unique. However, “even though your problems are non-unique, that doesn’t make them go away,” to paraphrase Neil Young. What will make them go away? Realizing that, beneath the surface, most of them rely on a handful of reusable patterns.
I’ll show you those patterns, so you can reuse them in your work or job interview, regardless of data or industry. Data is always just that – data. All samples will be inside. PostgreSQL Based on the coding interview questions StrataScratch. Then I will relate them to real business situations.

# 1. Joins + Filters: Finding the right subset
Question: Movie Duration Match from Amazon
Work: Developing a feature that recommends individual movies from Amazon’s content database that fit a given flight duration.
For Flight 101, look for movies that have a runtime less than or equal to the duration of the flight. The output should contain a list of recommended movies for the flight, incl flight_id, movie_idand movie_duration.
Solution:
SELECT fs.flight_id,
ec.movie_id,
ec.duration AS movie_duration
FROM flight_schedule fs
JOIN entertainment_catalog ec ON ec.duration <= fs.flight_duration
WHERE fs.flight_id = 101
ORDER BY ec.duration;Output:
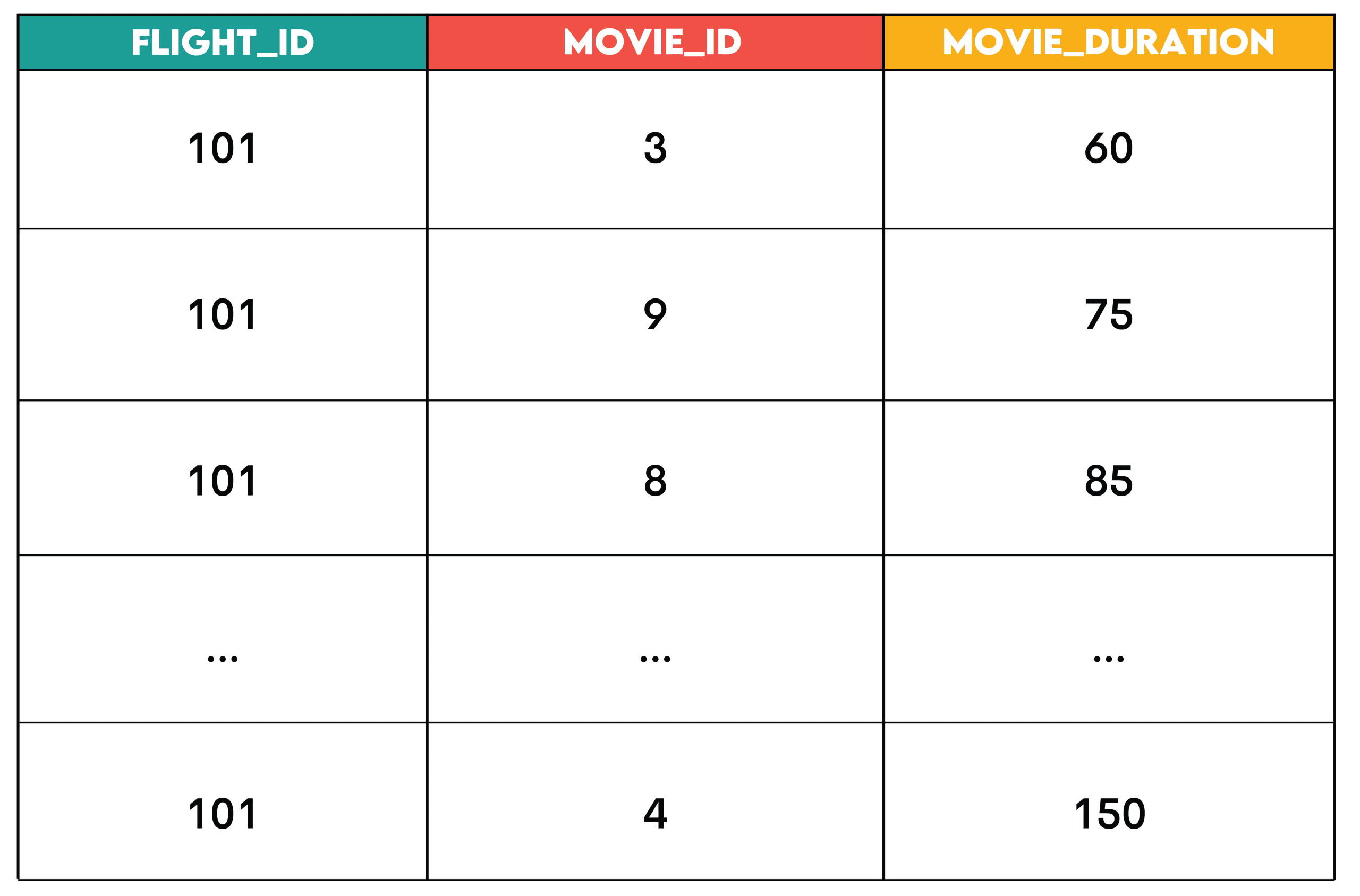
Pattern: JOIN + FILTER is the pattern where you join two datasets and filter rows (among them WHERE Before or within collection HAVING after collection) based on conditions.
This is the series.

- Identify the base table: the dataset that defines what you are analyzing (
flight_schedule) - Include supplementary data: datasets that include context or attributes (
entertainment_catalog) - Apply filters: Remove rows you don’t need (
WHERE fs.flight_id = 101)
// Business use
- HR: Incorporating employees with their working hours to identify overtime
- Retail: Joining orders with product details to analyze product category performance
- Streaming: Engaging users with their sessions to find active viewers
# 2. Functions of Window: Classification and Layout
Question: Top posts per channel from Meta
Work: Identify the top 3 posts with the highest like count for each channel. Assign a rank to each post based on the number of likes it has, with a difference in rank when posts have the same number of likes.
The output should show the channel name, post ID, post creation date, and like count for each post.
Solution:
WITH ranked_posts AS
(SELECT post_id,
channel_id,
created_at,
likes,
RANK() OVER (PARTITION BY channel_id ORDER BY likes DESC) AS post_rank
FROM posts
WHERE likes > 0)
SELECT c.channel_name,
r.post_id,
r.created_at,
r.likes
FROM ranked_posts AS r
JOIN channels AS c ON r.channel_id = c.channel_id
WHERE r.post_rank <= 3;Output:
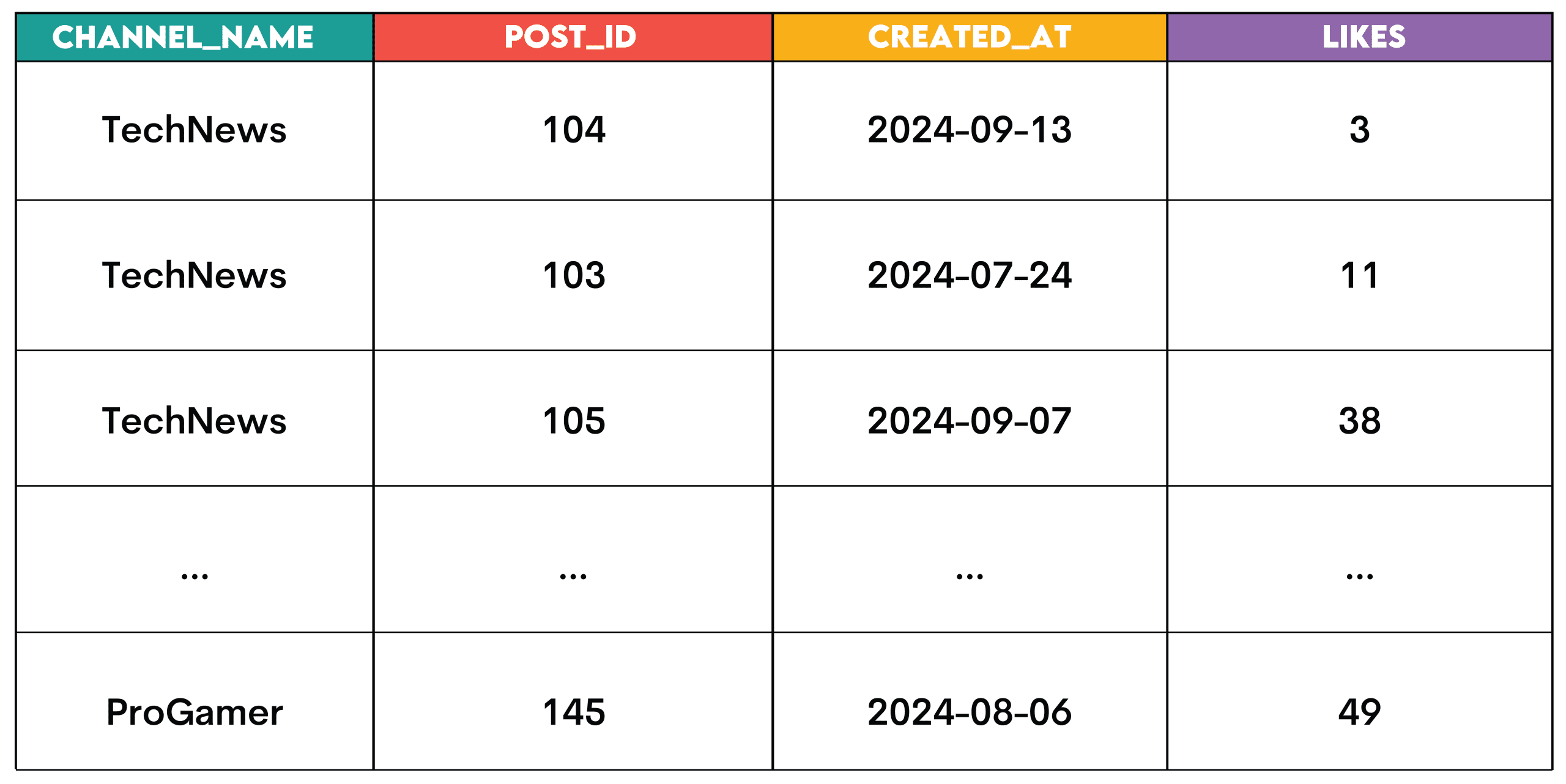
Pattern: These are the window functions used for classification.
RANK(): classification with a differenceDENSE_RANK(): classification without differentiationROW_NUMBER(): Unique sequence with no relation
When grading, follow this pattern.
- Divide the data: Define the logical grouping you are analyzing (
PARTITION BY channel_id) - Order within each distribution: specify a ranking or time order (
ORDER BY likes DESC) - Apply the Hierarchical Window function –
RANK(),DENSE_RANK()orROW_NUMBER() OVER()Depends on the job
// Business use
This pattern is used to identify top performers, for example:
- Sales: Top sales representatives per territory.
- Education: Classifying students according to test scores in each class
- Logistics: Ranking delivery drivers by completed deliveries in each region
# 3. Aggregation + grouping: roll-up pattern
Question: Same day orders from Walmart
Work: Find customers who started a session and placed an order on the same day. Calculate the total number of orders placed that day and the total order value for that day.
Solution:
SELECT s.user_id,
s.session_date,
COUNT(o.order_id) AS total_orders,
SUM(o.order_value) AS total_order_value
FROM
(SELECT DISTINCT user_id,
session_date
FROM sessions) s
JOIN order_summary o ON s.user_id = o.user_id
AND s.session_date = o.order_date
GROUP BY s.user_id, s.session_date;Output:
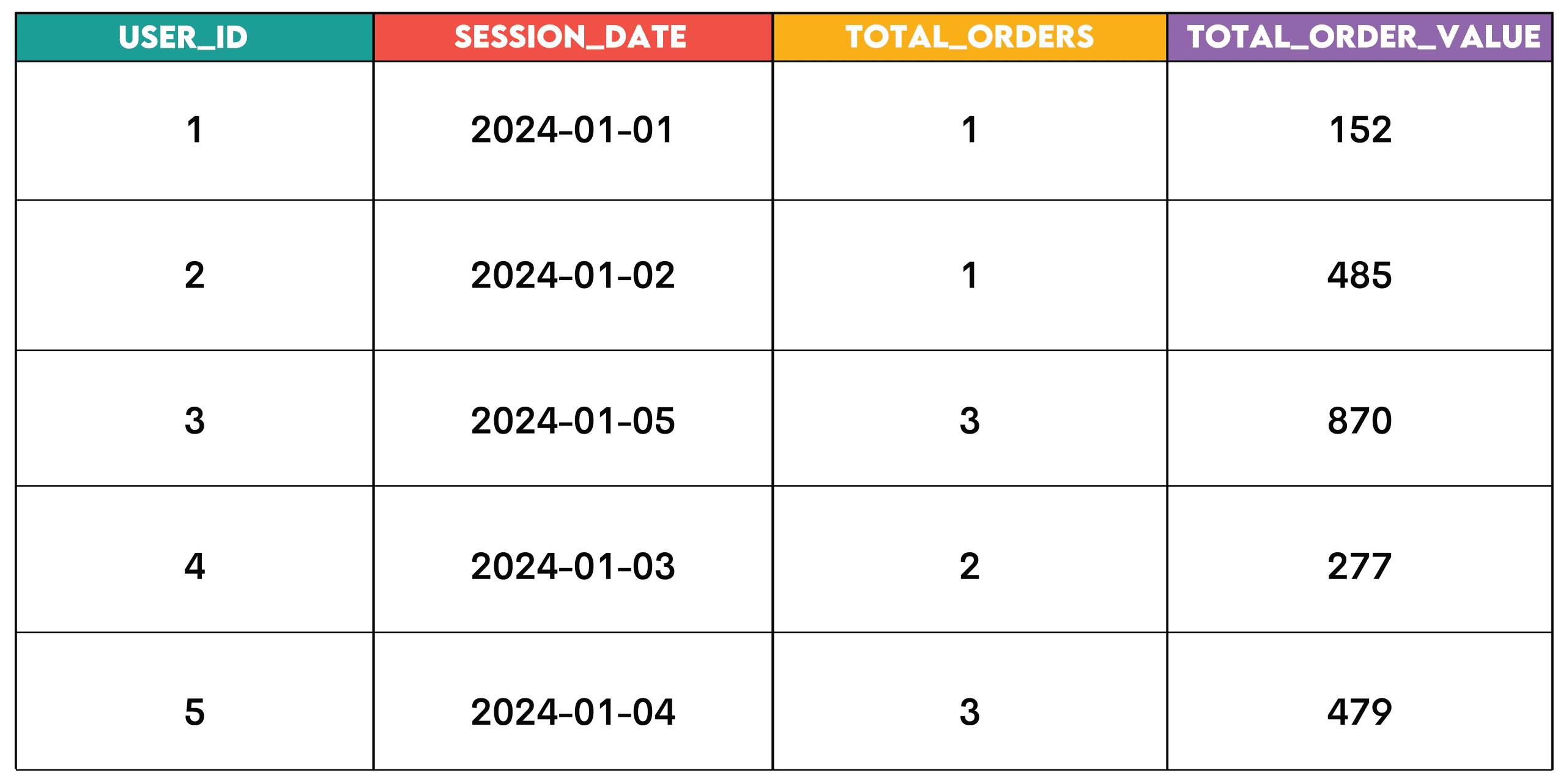
Pattern: This pattern is for summarizing data, such as customers, dates, products, or other analytical dimensions.
This is the setting.

- Identify the grouping dimension: the column you want to group by (
user_idAndsession_date) - Group data: Use
GROUP BYOn selected dimensions to group data - Sum the matrix: Sum the values for each group using the sum functions.
- Filter aggregate results (optional): Use
HAVINGKeeping only specific groups in terms of overall value
// Business use
- E-commerce: Orders and revenue per user per day
- SaaS: Logins per user per week
- Finance: Transactions per account per quarter
# 4. Pivoting: Converting rows to columns
Question: Highest paid from the city of San Francisco
Work: Create a pivot table that shows the highest payout for each employee in each year, sorted by employee name in ascending order. The table should show the years 2011, 2012, 2013 and 2014.
Solution:
SELECT employeename,
MAX(pay_2011) AS pay_2011,
MAX(pay_2012) AS pay_2012,
MAX(pay_2013) AS pay_2013,
MAX(pay_2014) AS pay_2014
FROM
(SELECT employeename,
CASE
WHEN year = 2011
THEN totalpay
ELSE 0
END AS pay_2011,
CASE
WHEN year = 2012
THEN totalpay
ELSE 0
END AS pay_2012,
CASE
WHEN year = 2013
THEN totalpay
ELSE 0
END AS pay_2013,
CASE
WHEN year = 2014
THEN totalpay
ELSE 0
END AS pay_2014
FROM sf_public_salaries) pmt
GROUP BY employeename
ORDER BY employeename;Output:
![]()
Pattern: Pivoting changes row values to columns. This is useful when comparing metrics across years, categories, or segments.
This is the setting.
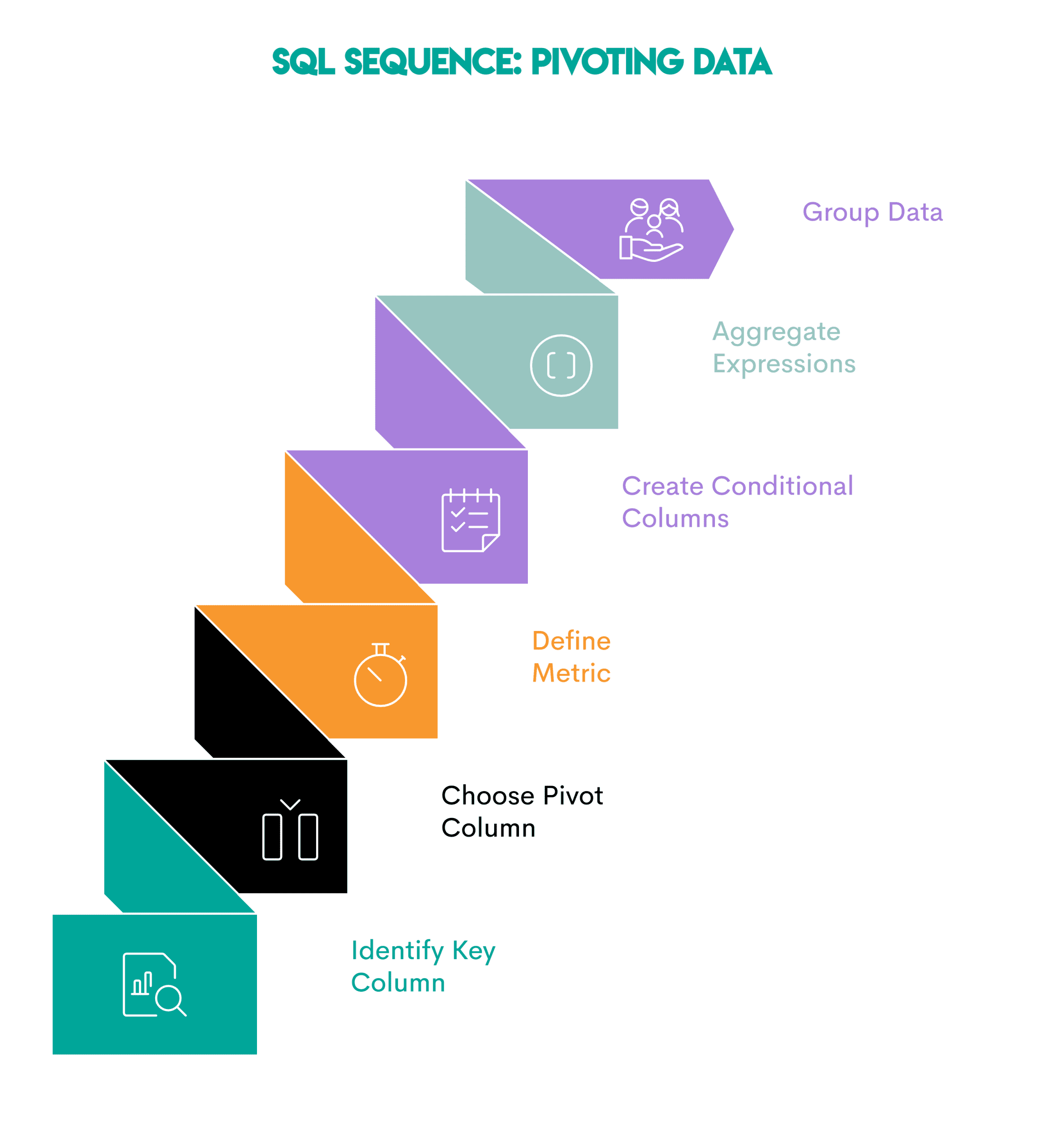
- Identify the key column: the column you want to display as a row (
employeename) - Select Pivot Column: The field whose unique values will become the new column (
year) - Define Metric: Specify the metric you want to calculate and collect (
totalpay) - Create a conditional column using:
CASE WHEN(OrPIVOTwhere supported) to assign values to each column based on the pivot column - Aggregate the conditional expression in the outer query: Aggregate each pivot column.
- Group data: Use
GROUP BYOn the key column to group the output
// Business use
- Finance: Comparing earnings quarter to quarter
- HR: Comparison of salaries throughout the year
- Retail: Comparing monthly sales totals
# 5. Aggregate metrics: growth, sustainability, and progress
Question: Earnings over time from Amazon
Work: Calculate the 3-month rolling average of total revenue from purchases. Returns—represented by negative purchase values—should not be included in the calculation.
The output should show year-month (YYYY-MM) and rolling averages, sorted from earliest to most recent month.
Solution:
SELECT t.month,
AVG(t.monthly_revenue) OVER (ORDER BY t.month ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS avg_revenue
FROM
(SELECT to_char(created_at::date, 'YYYY-MM') AS month,
SUM(purchase_amt) AS monthly_revenue
FROM amazon_purchases
WHERE purchase_amt > 0
GROUP BY to_char(created_at::date, 'YYYY-MM')
ORDER BY to_char(created_at::date, 'YYYY-MM')
) t
ORDER BY t.month ASC;Output:
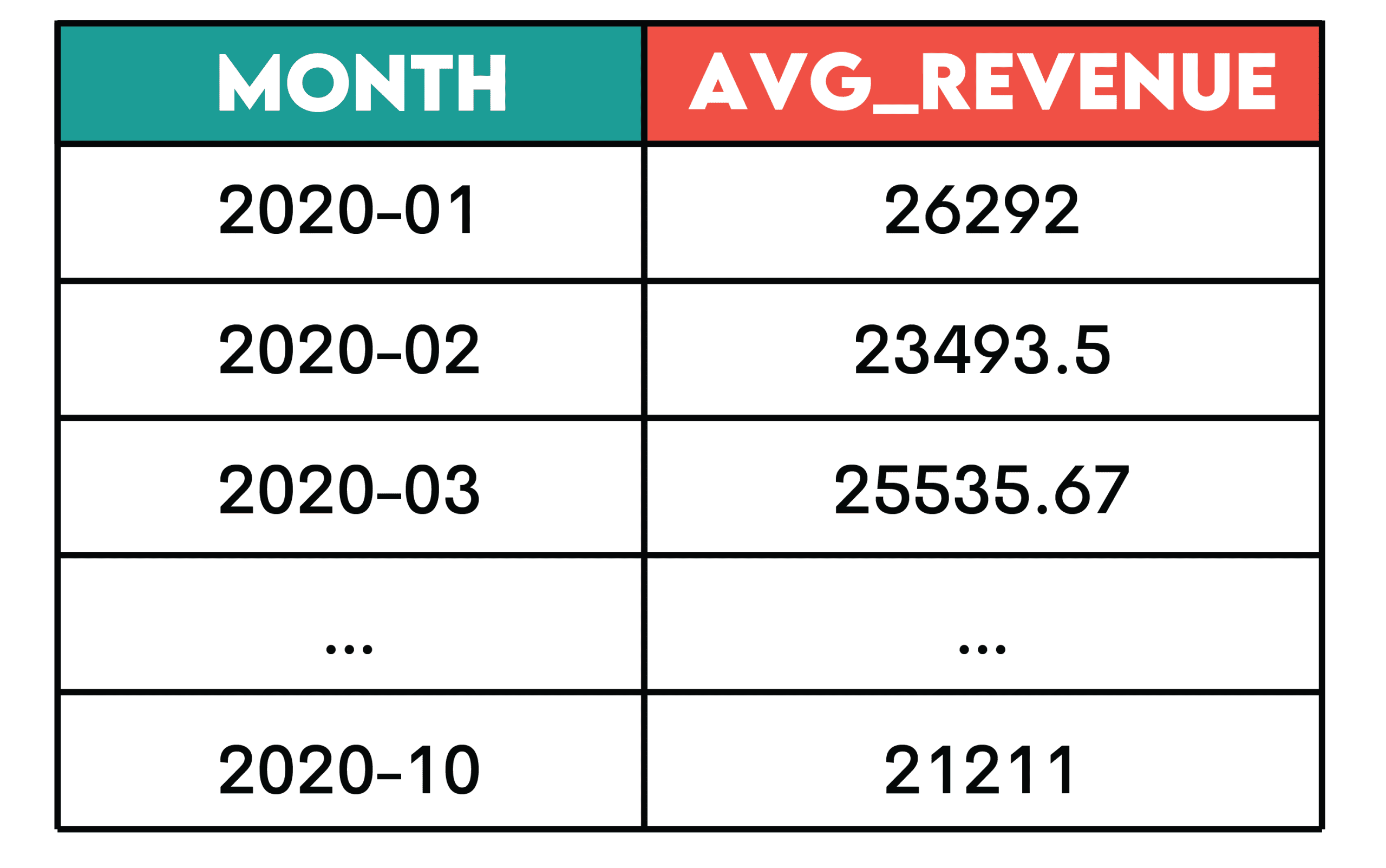
Pattern: Aggregate metrics (such as running totals, moving averages, or running counts) are used to understand trends rather than showing individual time periods separately.
This is the setting.

- Pre-aggregation by time period (optional): Summarize the analytics data into a total by the desired time period (all displayed in the query).
- Apply an aggregate function: Use an aggregate function on the column you want to aggregate in the main query.
- Convert an aggregate function to a window function: use
OVER()Clause - Sort the time intervals: sort the data within the distribution by date so that the aggregate calculation is applied correctly (
ORDER BY t.month) - Specify Window Frame: Specify the number of previous or subsequent periods to include in the total calculation (
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
// Business use
- E-commerce: Total revenue is running.
- SaaS: Aggregate Active Users
- Product Analytics: Cohort Retention Curves
- Finance: Trailing Average
- Operations: Rolling total support tickets
# 6. Funnel Analysis: Tracking sequential behavior
Question: Penetration analysis by Spotify
Work: We have to revise the requirements. The new task is to measure how users progress through the stages of engagement on Spotify. The stages of engagement are:
- Active — The user had at least one session.
- Engaged – User had 5+ sessions.
- Power User – User has had 5+ sessions and at least 10 listening hours in the last 30 days
For each country, calculate how many users reach each stage and the overall conversion rate from first activity to power user status.
Solution:
WITH base AS (
SELECT country,
user_id,
sessions,
listening_hours,
last_active_date
FROM penetration_analysis
),
stage_1 AS (
SELECT DISTINCT user_id, country
FROM base
WHERE sessions > 0
),
stage_2 AS (
SELECT DISTINCT user_id, country
FROM base
WHERE sessions >= 5
),
stage_3 AS (
SELECT DISTINCT user_id, country
FROM base
WHERE sessions >= 5 AND listening_hours >= 10
)
SELECT country,
COUNT(DISTINCT s1.user_id) AS users_started,
COUNT(DISTINCT s2.user_id) AS engaged_5_sessions,
COUNT(DISTINCT s3.user_id) AS power_users,
ROUND(100.0 * COUNT(DISTINCT s3.user_id) / NULLIF(COUNT(DISTINCT s1.user_id), 0), 2
) AS conversion_rate
FROM stage_1 s1
LEFT JOIN stage_2 s2 USING (user_id, country)
LEFT JOIN stage_3 s3 USING (user_id, country)
GROUP BY country;Output:
![]()
Pattern: Funnel analysis shows how users move through a series of ordered stages. Because the analysis depends on completing the previous one, it focuses on conversions and drop-offs.
This is the setting.
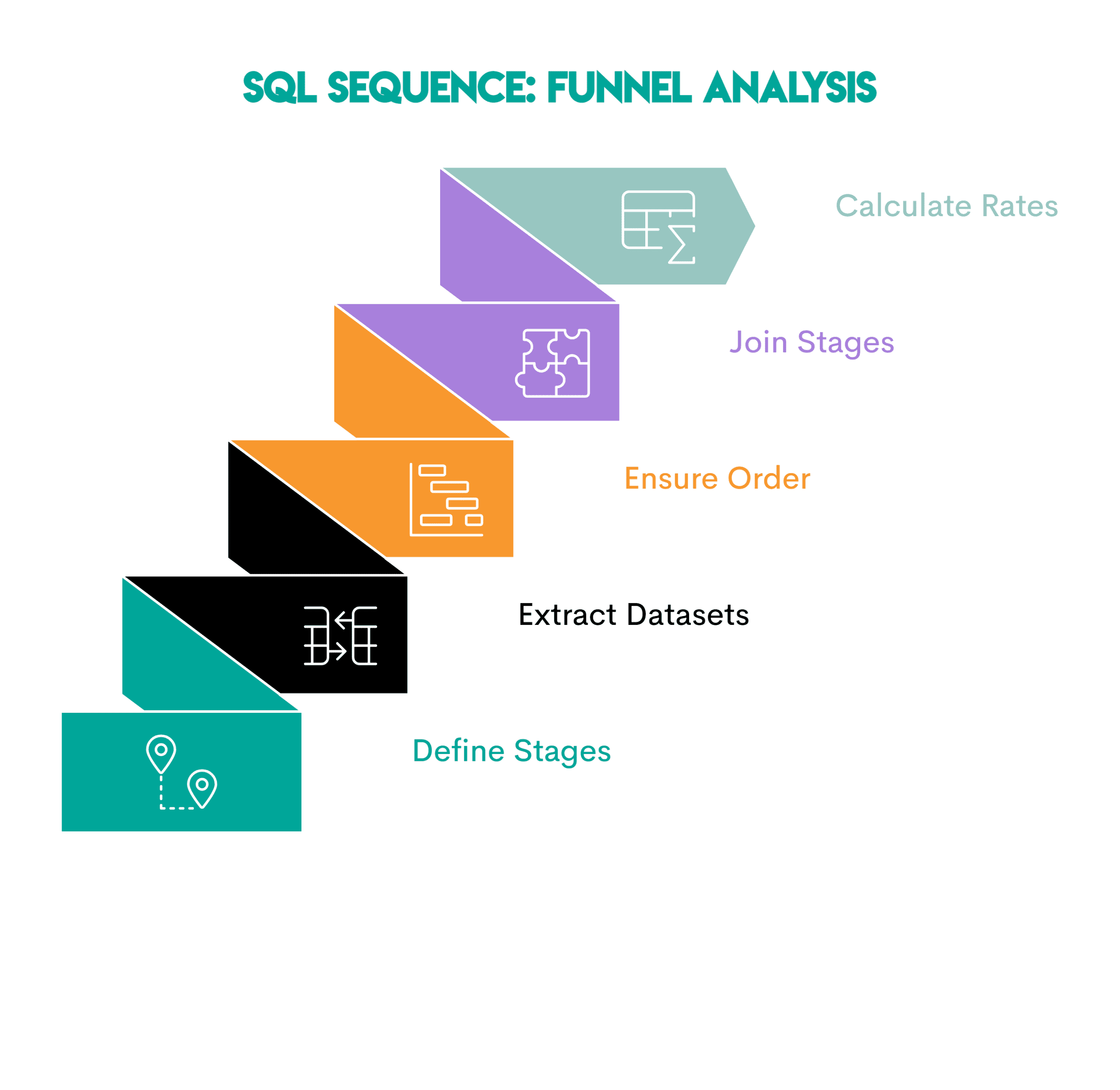
- Define steps: Identify each step that the user must complete.
- Extract one dataset per step: write a common table expression (CTE) or subquery for each step, containing only the users who are eligible
- Ensure stage order: If needed, filter by timestamp or sequence rules so that later stages come after earlier ones
- Join stages: Join using stage datasets.
LEFT JOINTo see how many users reach each step. - Count users and calculate conversion rates: Compare the number of users at each stage.
// Business use
- E-Commerce: View -> Add to Cart -> Purchase
- SaaS: Signup -> Activate -> Maintain
- Streaming: Listen once -> Engage regularly -> Become a power user.
# 7. Time-based comparisons: Period-over-period metrics
Question: Daily violation counts from the City of San Francisco
Work: Determine the change in the number of daily violations by calculating the difference between the number of current and previous violations as of the inspection date.
Show the change in inspection date and number of daily violations, from earliest to most recent inspection ordered.
Solution:
SELECT inspection_date::DATE,
COUNT(violation_id) - LAG(COUNT(violation_id)) OVER(ORDER BY inspection_date::DATE) AS diff
FROM sf_restaurant_health_violations
GROUP BY 1
ORDER BY 1;Output:
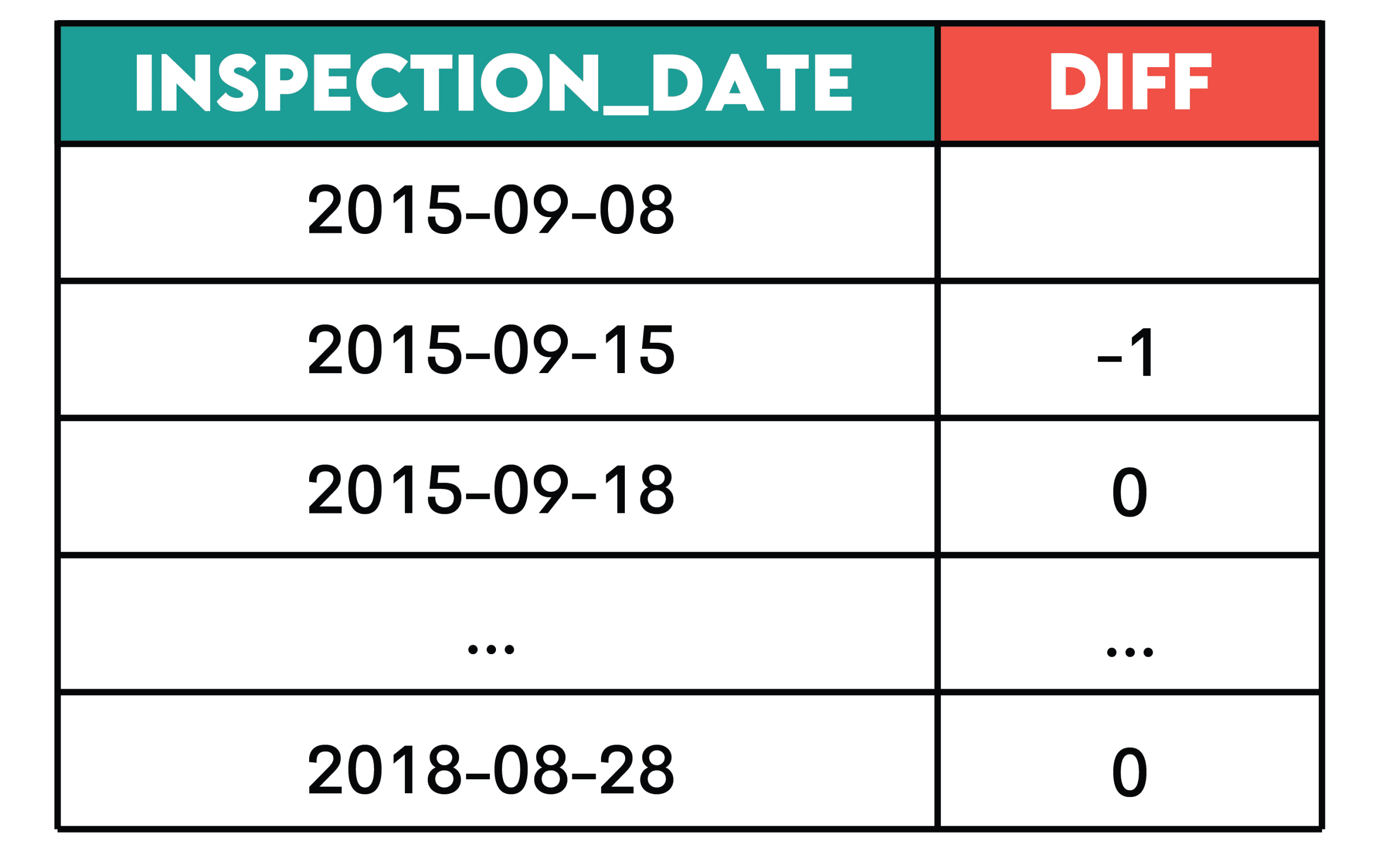
Pattern: This pattern is useful when you want to see how a metric changes over time.
This is the setting.
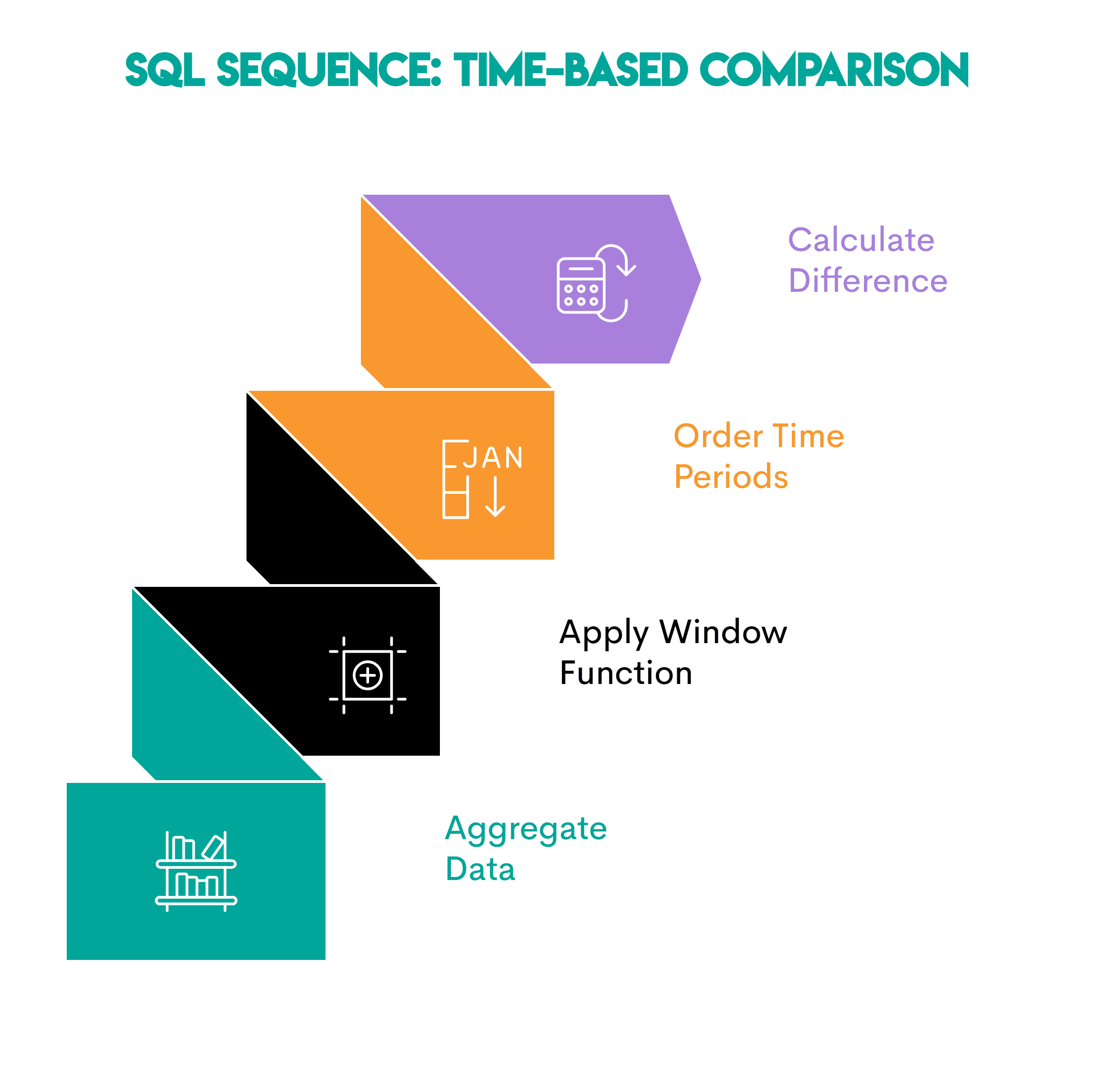
- Aggregate Data: Summary of events over time periods (daily/weekly/monthly totals)
- Apply window function: Use
LAG()orLEAD()To access values from the previous or following period - Set the time period: Use
ORDER BYIn clauseOVER()To sort the data chronologically so that comparisons are accurate. - Calculate the difference: Subtract the previous value from the current value to get the difference.
// Business use
- Product: Daily changes to active users
- Operations: Daily changes in support volume
- Finance: Month-to-month revenue delta
# wrap up
Internalize these seven patterns and watch data analysis problems dissolve before your eyes. I am sure they will be helpful in many business situations and job interviews.
Net Rosiedi A data scientist and product strategist. He is also an adjunct professor teaching analytics, and the founder of StrataScratch, a platform that helps data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers all things SQL.