

Photo by author
# Introduction
Retrieval-Augmented Generation (RAG) systems are, simply put, a natural evolution of standalone large language models (LLMs). RAG overcomes several key limitations of classical LLM, e.g Model hallucinations or lack of up-to-date, relevant knowledge needed to generate fact-based answers to user questions.
In a related article series, Understanding RAGwe provided a comprehensive overview of RAG systems, their features, practical considerations and challenges. We now synthesize some of these lessons and combine them with state-of-the-art trends and techniques to describe seven critical steps considered essential to mastering the development of RAG systems.
These seven phases correspond to different phases or components of the RAG environment, as shown in the numbered labels ((1) to (7)) in the diagram below, which illustrates the classic RAG architecture:
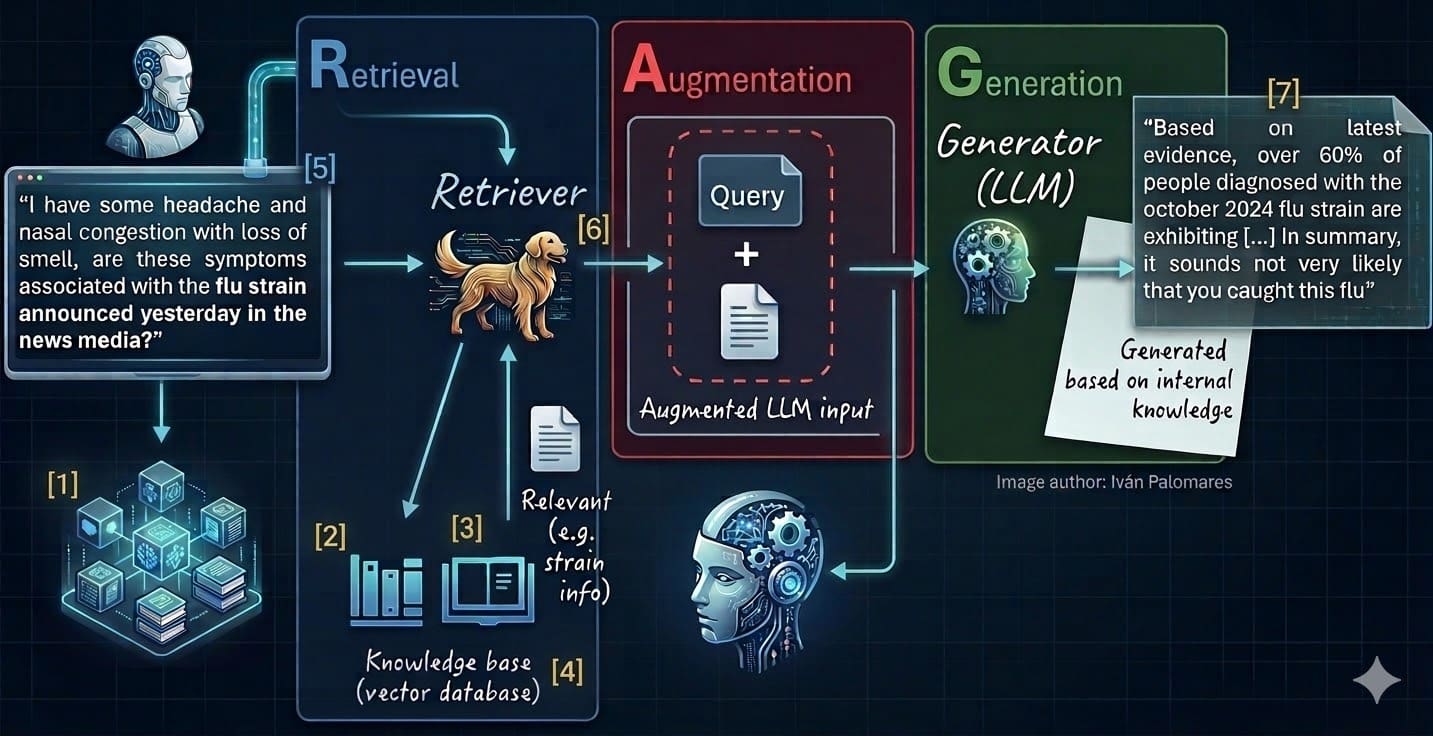
7 Steps to Mastering RAG Systems (see numbered labels 1-7 and list below)
- Select and clear data sources.
- Fragmentation and division
- Embedding/Vectorization
- Populate the vector database.
- Question vectorization
- Retrieve the relevant context.
- Prepare a ground response.
# 1. Selection and cleaning of data sources
The principle of “garbage in, garbage out” holds its maximum importance in RAG. Its value is directly proportional to the relevance, quality and cleanliness of the source text data it can retrieve. To ensure high-quality knowledge bases, identify high-value data silos and periodically audit your bases. Before ingesting raw data, perform an effective cleaning process through robust pipelines that apply key steps such as removing personally identifiable information (PII), eliminating duplicates, and dealing with other noisy elements. It is a continuous engineering process that is applied every time new data is added.
You can read. This article To review data cleaning techniques.
# 2. Shredding and distribution of papers
Many examples of textual data or documents, such as literary novels or PhD theses, are too large to be embedded as a single data instance or unit. Chunking consists of dividing a long text into smaller parts that retain semantic significance and maintain contextual integrity. This requires a careful approach: lots of chunks (tolerating possible loss of context), but not too few — big chunks affect semantic search later!
There are various chunking approaches: from those based on character count to those driven by logical boundaries such as paragraphs or sections. The Llama Index And Lang ChinaWith their respective Python libraries, can certainly help in this task by implementing more advanced distribution mechanisms.
Chunking can also consider the overlap between parts of a document to maintain consistency in the retrieval process. For example, this is what chunking looks like on a small, toy-sized piece of text:
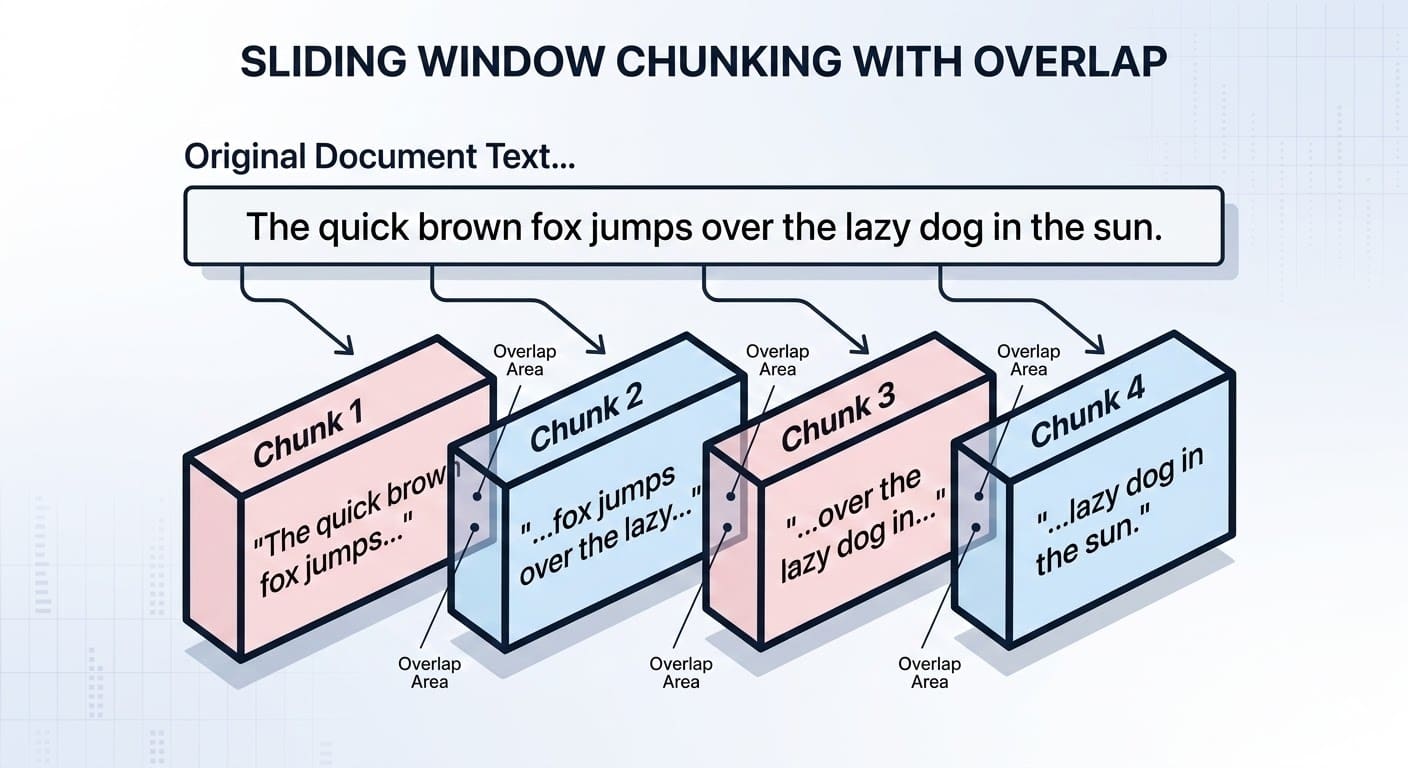
Selecting Documents with Overlap in RAG Systems | Photo by author
i This episode In the RAG series, you can also learn the additional role of the document cutting process in managing the context size of RAG inputs.
# 3. Embedding and vectorizing documents
Once the documents are fragmented, the next step is to translate them into “machine language” before storing them securely in the knowledge base: no. This is usually done by converting each text into a vector embedding—a dense, high-dimensional numerical representation that captures the semantic properties of the text. In recent years, specialized LLMs have been created to do this work: they are called embedding models and include well-known open source options such as A huggable face all-MiniLM-L6-v2.
Learn more about embedding and their advantages over classical text representation methods. This article.
# 4. Populating the vector database
Unlike traditional relational databases, vector databases are designed to efficiently enable search through high-dimensional arrays (embeddings) that represent text documents—a key step in RAG systems for retrieving relevant documents upon user query. Both like open source vector stores. FAISS Or freemium alternatives like Pinecone exists, and can provide optimal solutions, thereby bridging the gap between human-readable text and mathematical-like vector representations.
An excerpt of this code is used to split the text (see point 2 above) and populate a local, free vector database using LangChain. Chroma – Assuming we have a long document to store in a file. knowledge_base.txt:
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# Load and chunk the data
docs = TextLoader("knowledge_base.txt").load()
chunks = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50).split_documents(docs)
# Create text embeddings using a free open-source model and store in ChromaDB
embedding_model = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
vector_db = Chroma.from_documents(documents=chunks, embedding=embedding_model, persist_directory="./db")
print(f"Successfully stored {len(chunks)} embedded chunks.")Read more about vector databases Here.
# 5. Vectorizing queries
User gestures expressed in natural language do not correspond directly to stored document vectors: they must also be translated using the same embedding mechanism or model (see step 3). In other words, a single query vector is created and compared to the vectors stored in the knowledge base to retrieve, based on the similarity matrix, the most relevant or similar documents.
Some advanced methods for query vectorization and optimization are described. This part Of Understanding RAG Series
# 6. Retrieving relevant context
Once your query is vectorized, the RAG system’s retriever performs a similarity-based search to find the closest matching vector (document fragment). While traditional top-k approaches often work, advanced methods such as fusion retrieval and reclassification can be used to improve how the retrieved results are processed and integrated as part of the final, enriched prompt for LLM.
check This related article To learn more about these advanced mechanisms. likewise, Managing context windows Another important process to implement is when the LLM’s capabilities to handle very large inputs are limited.
# 7. Developing ground responses
Finally, the LLM comes into the scene, takes the user query augmented with the retrieved context, and is instructed to answer the user query using that context. In a properly designed RAG architecture, following the previous six steps, this usually leads to more accurate, defensible answers that may include references to our own data used to build the knowledge base.
At this point, assessing response quality is important to measure how the overall RAG system behaves, and signaling when the model may be needed. Fine tuning. Assessment frameworks has been established for this purpose.
# The result
RAG systems or architectures have become an almost indispensable aspect of LLM-based applications, and are rarely lacking today on a commercial, large scale. RAG makes LLM applications more reliable and knowledge-based, and they help these models generate evidence-based ground responses, sometimes predicated on privately owned data in organizations.
This article summarizes seven key steps to mastering the process of building RAG systems. Once you have these basic knowledge and skills down, you’ll be in a good position to develop better LLM applications that unlock enterprise-grade performance, accuracy, and transparency—not possible with the leading models used on the Internet.
Iván Palomares Carrascosa He is a leader, author, speaker, and consultant in AI, Machine Learning, Deep Learning and LLMs. He trains and guides others in using AI in the real world.