

Photo by editor
# Introduction
Data science projects Typically exploratory Pythons start as notebooks but need to be moved to production settings at some stage, which can be difficult if not carefully planned.
Quantum Black’s framework, Cadrois an open source tool that bridges the gap between experimental notebooks and production-ready solutions by translating concepts related to project structure, scalability, and reproducibility into practice.
This article introduces and explores key features of Kedro, leading to a better understanding of its basic concepts before diving deeper into the framework for tackling real data science projects.
# Getting started with Cadro
The first step to using Kedro, of course, is to install it in our running environment, ideally an IDE — Kedro cannot be fully exploited in a notebook environment. Open your favorite Python IDE, for example, VS Code, and in the connected terminal type:
Next, we create a new Kedro project using this command:
If the command works well, you’ll be asked a few questions, including the name of your project. We will name it. Churn Predictor. If the command does not work, it may be due to a conflict related to installing multiple versions of Python. In this case, the cleanest solution is to work in a virtual environment within your IDE. Here are some quick workaround commands to create one (ignore them if the previous command to create a Cadro project already worked!):
python3.11 -m venv venv
source venv/bin/activate
pip install kedro
kedro --versionThen select the following Python interpreter in your IDE to work from now on. ./venv/bin/python.
At this point, if everything went well, you should have a complete project structure on the left (in the ‘EXPLORER’ panel in VS Code) churn-predictor. In Terminal, let’s go to the main folder of our project:
Time to get a glimpse of Cadro’s core features through our newly created project.
# Exploring Cadre’s Basic Elements
The first element we’ll introduce – and create ourselves – is the Data Catalog. In Kedro, this element is responsible for separating data definitions from the main code.
An empty file is already created as part of the project structure that will serve as the data catalog. We just need to find it and populate it with content. In IDE Explorer, in churn-predictor Go to Project conf/base/catalog.yml and open that file, then add the following:
raw_customers:
type: pandas.CSVDataset
filepath: data/01_raw/customers.csv
processed_features:
type: pandas.ParquetDataset
filepath: data/02_intermediate/features.parquet
train_data:
type: pandas.ParquetDataset
filepath: data/02_intermediate/train.parquet
test_data:
type: pandas.ParquetDataset
filepath: data/02_intermediate/test.parquet
trained_model:
type: pickle.PickleDataset
filepath: data/06_models/churn_model.pklBriefly, we have just defined five datasets (not yet created), each with an accessible key or name: raw_customers, processed_featuresand so on. The main data pipeline we will build later must be able to refer to these datasets by their name, therefore abstracting and completely separating input/output operations from the code.
We will need something now. Data which serves as the first dataset in the data catalog definitions above. For this example you can take This sample of the generated customer data, download it, and integrate it into your Kedro project.
Next, we navigate. data/01_rawcreate a new file named customers.csvand add the contents of the example dataset we will use. The easiest way is to view the “raw” contents of the dataset file in GitHub, select all, copy and paste it into your newly created file in the Cadro project.
Now we will create a Cadro. The pipelinewhich will define the data science workflow that will be applied to our raw data set. In Terminal, type:
kedro pipeline create data_processingThis command creates several Python files inside. src/churn_predictor/pipelines/data_processing/. Now, we’ll open nodes.py And paste the following code:
import pandas as pd
from typing import Tuple
def engineer_features(raw_df: pd.DataFrame) -> pd.DataFrame:
"""Create derived features for modeling."""
df = raw_df.copy()
df('tenure_months') = df('account_age_days') / 30
df('avg_monthly_spend') = df('total_spend') / df('tenure_months')
df('calls_per_month') = df('support_calls') / df('tenure_months')
return df
def split_data(df: pd.DataFrame, test_fraction: float) -> Tuple(pd.DataFrame, pd.DataFrame):
"""Split data into train and test sets."""
train = df.sample(frac=1-test_fraction, random_state=42)
test = df.drop(train.index)
return train, testThe two functions we just defined do work. Nodes that can apply changes to a dataset as part of a reproducible, modular workflow. The first applies some simple, idealized feature engineering by creating multiple derived features from the raw features. Meanwhile, the second function defines the partitioning of the dataset into training and test sets, e.g., for further downstream machine learning modeling.
In the same subdirectory is another Python file: pipeline.py. Let’s open it and add the following:
from kedro.pipeline import Pipeline, node
from .nodes import engineer_features, split_data
def create_pipeline(**kwargs) -> Pipeline:
return Pipeline((
node(
func=engineer_features,
inputs="raw_customers",
outputs="processed_features",
name="feature_engineering"
),
node(
func=split_data,
inputs=("processed_features", "params:test_fraction"),
outputs=("train_data", "test_data"),
name="split_dataset"
)
))Part of the magic happens here: look at the names used for the inputs and outputs of the nodes in the pipeline. Just like Lego pieces, Here we can flexibly refer to different dataset definitions in our data catalog.of course, starting with the dataset we created earlier.
There are two final configuration steps left to get everything working. The proportion of test data for a distribution node is defined as a parameter that needs to be passed. In Kedro, we define these “external” parameters by adding them to the code. conf/base/parameters.yml file Let’s add the following to this currently empty configuration file:
Also, by default, the Cadro project implicitly imports modules from the PySpark library, which we won’t really need. i settings.py (within the “src” subdirectory), we can disable it by commenting out and editing the first few existing lines of code below:
# Instantiated project hooks.
# from churn_predictor.hooks import SparkHooks # noqa: E402
# Hooks are executed in a Last-In-First-Out (LIFO) order.
HOOKS = ()Save all changes, make sure you have Pandas installed in your running environment, and get ready to run the project from the IDE terminal:
This may or may not work at first, depending on the version of Cadro installed. If it doesn’t work and you get one. DatasetErroris a possible solution pip install kedro-datasets or pip install pyarrow (or maybe both!), then try running again.
Hopefully, you can get a bunch of ‘INFO’ messages informing you about the various stages of the data workflow. This is a good sign. i data/02_intermediate In the directory, you can find several Parquet files containing the results of data processing.
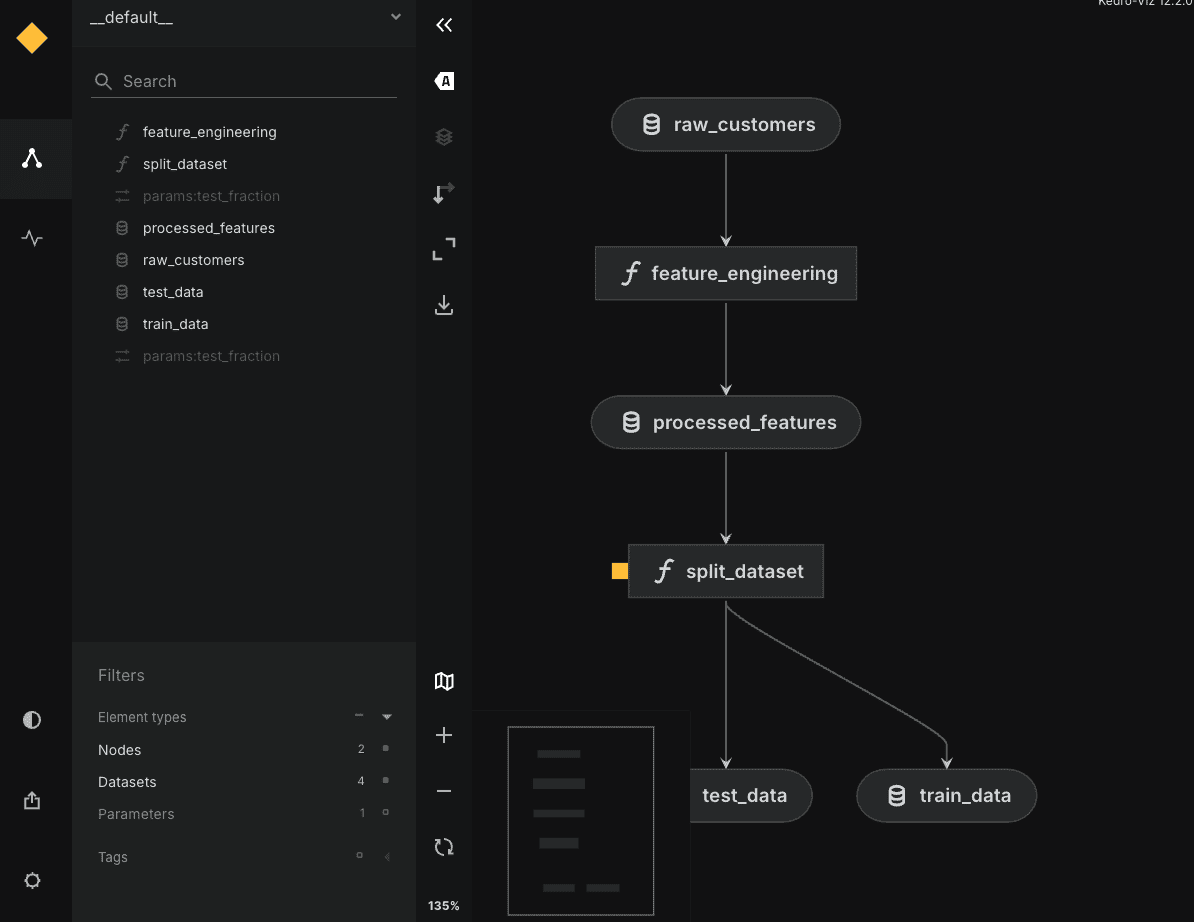
For wrapping, you can optionally. pip install kedro-viz And run kedro viz To open an interactive graph of your shiny workflow in your browser, as shown below:
# wrap up
We’ll leave further exploration of this tool for a possible future article. If you got here, you were able to create your first Kedro project and learn about its basic components and features, understanding how they interact along the way.
Well done!
Iván Palomares Carrascosa He is a leader, author, speaker, and consultant in AI, Machine Learning, Deep Learning and LLMs. He trains and guides others in using AI in the real world.