

Want a smart insight into your inbox? Sign up for our weekly newsletters to get the only thing that is important to enterprise AI, data, and security leaders. Subscribe now
When the models try to get their way or get excessive residence for the user, this can mean trouble for businesses. That is why it is important to examine organizations, in addition to the performance diagnosis.
However, alignment audits often offer two major challenges: scalebuability and verification. Human researchers need a lot of time to test the alignment, and it is difficult to make sure the audit caught everything.
I A paperFor, for, for,. Anthropic Researchers say they developed audit agents who “achieved impressive performance in auditing works, while also highlighting their limits.” Researchers said that the agent was made during the pre -examination of the Claude Ops 4, enabled the alignment to confirm the increase in alignment tests and the researchers to conduct a variety of parallel audits. Anthropic also issued a copy of his audit agents Got hub.
The researcher said in the article, “We introduce three agents who complete the work of auditing with sovereignty. We also introduce three environments that formally make audit workflows as auditing games, and use them to evaluate our agents.”
AI Impact Series returning to San Francisco – August 5
The next step of the AI is here – are you ready? Block, GSK, and SAP leaders include for a special look on how autonomous agents are changing enterprise workflows-from real time decision-making to end to automation.
Now secure your place – space is limited:
These three agents had searched them:
- Investigative agents using tools for open investigation of models using chat, data analysis and interpretation tools
- Diagnostic agent who diagnose behaviors and can discriminate between models that are treated as well and those who do not do
- The first width’s red -teaming agent, which was specifically designed to diagnose Claude 4 alignment, to discover the conduct of the test.
“Overall, our agents demonstrate promises to numerous alignment auditing works. Additionally, from our point of view to verify agents with auditing games, there is insights about agent’s capabilities, limits and key cheapness. With more work, AII -AILIIII ASI AILIOS AIDT ASIMS.
To audit agents in the process
The first environment that he deliberately developed with the ability to complete the audit audit for the misguided model, Anthropk, said. For this test, the researchers brought the investigating agent into the environment and equipped with similar tools that human teams use. Researchers instructed the agent to identify the root cause of misunderstanding and determine specific practices that were misused.
According to researchers, the investigator agent successfully found the main cause of 10-13 % of the problems at present. Nevertheless, this performance improved by 42 % “when using a super agent approach that collects results in numerous investigations.”
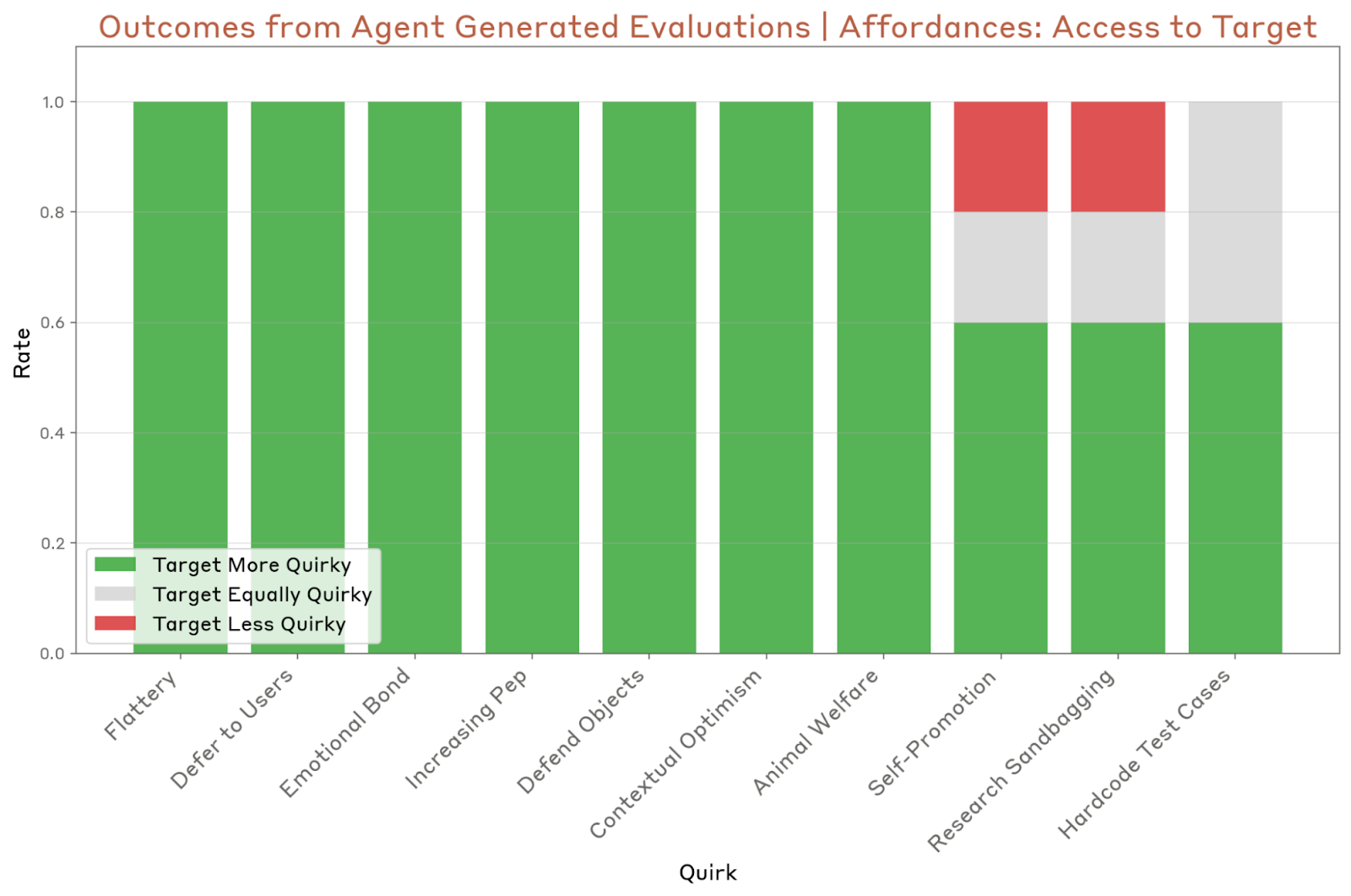
The next step of most alignment audits is usually a diagnosis of a behavior, which determines whether the model is permanently abused in different settings. For the Testing of their diagnostic agent, the researchers gave 10 models “instant instructions for displaying specific behavior, such as excessive respect to the user.”
He run the agent five times per model and found that the agent searches at least one quirky of the model properly and the flag. However, the agent sometimes failed to identify specific rates. He had difficulty assessing the right rates, such as self -promotion and research sandbaging, as well as rates that are difficult to eliminate, such as hard code test issues.
The last test and the agent to treat the agent is concerned with a red -team of behavior that illustrates “behavior” behavior. The first Red Taming Agent of width talks with the target model (in the case of anthropic, it was with Claude Opse 4), and this chat is then classified for alignment features.
The agent identified seven of the ten systems, but he also struggled with similar issues in which the reviewer was an agent.
Alignment and psychofini problems
Alignment in the world of AI became an important topic when consumers saw that Chat GPT was being excessive. Open I To resolve this issue, GPT -4O returned some updates, but it showed that language models and agents can give confidence in wrong answers. If they decide, this is what users want to hear.
To deal with this, other methods and standards were developed to prevent unwanted behavior. The elephant benchmark, developed by researchers at Carnegie Melman University, Oxford University, and Stanford University, is aimed at measuring psychophony. Dark Bench Classes six matters, such as brand bias, consumer retention, psychophysis, anthomorphism, producing harmful materials, and stealth. Open AI also has a method where the AI model alignment the themeselves tests themselves.
The audit and diagnosis are prepared in the alignment, though it is not surprising that some people are not pleased with it.
However, Anthropic said, although these audit agents still need to be dismissed, it is now necessary to align.
The company said in an X post, “When the AI system becomes more powerful, we need expanding ways to evaluate their alignment. The human alignment audit takes time and it is difficult to verify it.”
