

Robert Triggs / Android Authority
Another day, another big language model, but Openi has released its first openweight model (GPT-OSS) with Apache 2.0 licensing. Finally, you can run a version of Chat Jipt offline and give developers and American casual AI fans another powerful tool for free.
As usual, Openi makes some big claims about GPTOS capabilities. The model can apparently improve the O4-mini and the score very closely to the cost of the O3 Model-OPNI costs, very closely to the models of the most powerful and most powerful reasoning. However, the GPT-OSS model comes in great parameters of 120 billion, which requires some serious computing kit. For you and me, though, there is still a high -performing 20 billion parameter model available.
Can you run Chat GPT offline and free now? Well, it depends.
The theory, the 20 billion parameter model will run on a modern laptop or PC, provided you have a valuable RAM and a powerful CPU or GPU to reduce the number. Qualcomm has even claimed that it is excited about bringing the GPT-SOS to its computer platform-think about the PC instead of a mobile. Nevertheless, this question is begging: Is it possible now on a laptop or on your smartphone, fully offline and on -device fully offline and on -device? Well, it’s viable, but I will not recommend it.
What do you need to run GPTSOS?

Edgar Survints / Android Authority
Despite the general use of GPT-6 from 120 billion to 20 billion parameters, the official quantized model still weighs 12.2 GB. The Open AI 20B describes the requirements of 16GB for 16GB and 120b models of 80GB of VRAM. You need a machine that will be able to keep the whole thing in memory at the same time to achieve proper performance, which puts you firmly in the area of NVIDIA RTX 4080 of dedicated GPU memory – hardly anything we all have access to.
Small GPUVRAM PC LOO, you would like 16 GB system RAM if you can divide some of the models into GPU memory, and preferably a GPUFP4 has the potential to spoil precision data. For everything, such as ordinary laptops and smartphones, 16GB are really fixing it because you also need space for OS and apps. Based on my experience, 24 GB Ram is needed. My seventh general -level laptop, which is complete with the Snapdragon X processor and 16GB RAM, worked in a credible decent civilized 10 tokens in a second, but even though every other application was closed, it was barely placed on it.
Despite its low size, GPTOS 20B requires plenty of RAM and a powerful GPU to run easily.
Of course, with the 24GB of Ram ideal, the majority of smartphones cannot run it. Even the AI leader tops 16 GB RAM like Pixel 9 Pro XL and Galaxy S25 Ultra, and this is not accessible. Thankfully, my ROG Phone 9 Pro has a great 24GB of RAM – enough to start me.
How to run GPT-SOS on the phone

Robert Triggs / Android Authority
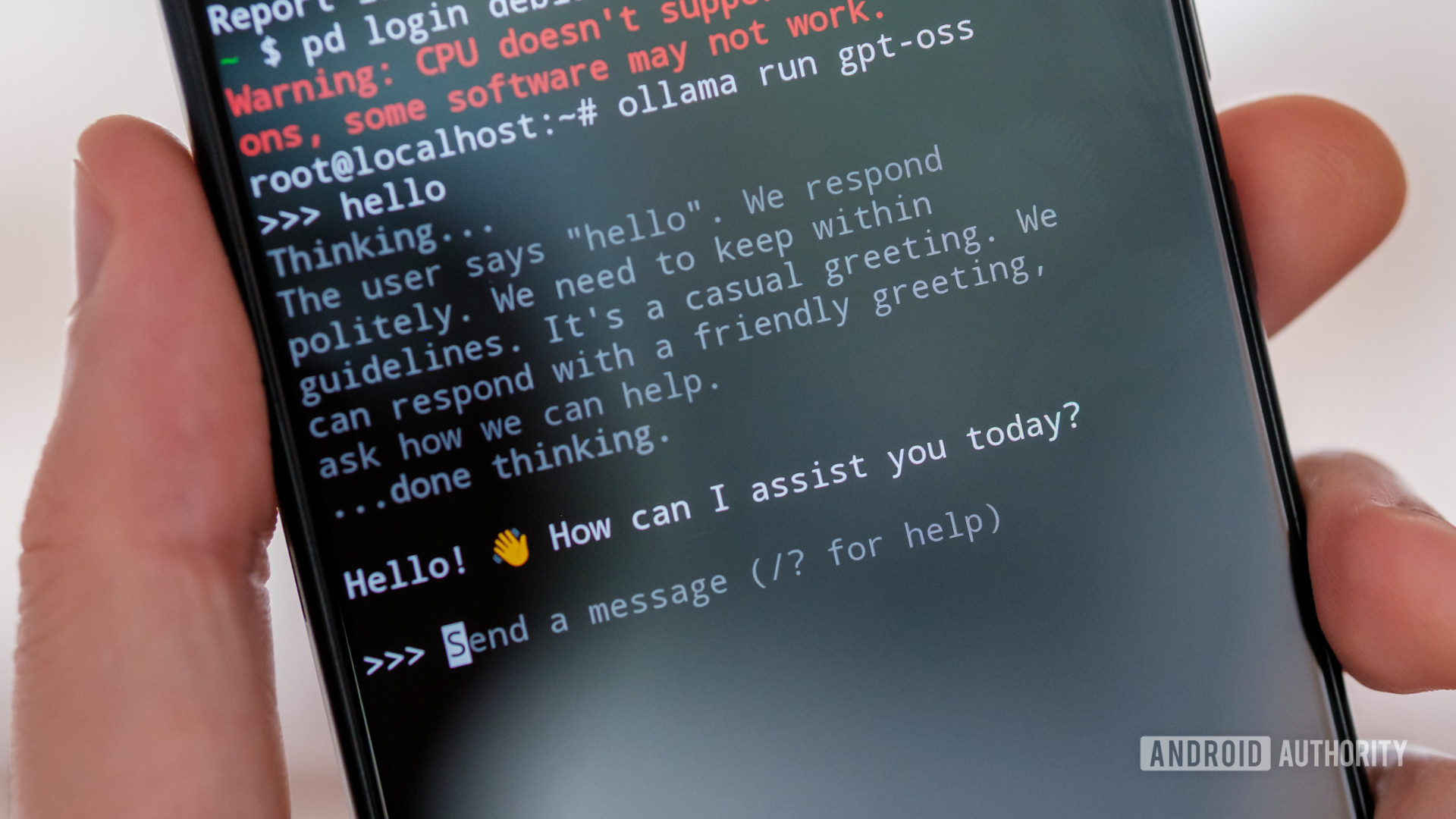
On my Android smartphone, my first attempt to run the GPT-SOS, I turned to the growing selection of LLM apps that allows you to run offline model, which includes Pocket AI, Lalma Chat, and LM playground.
However, these apps either did not have the model available or they could not successfully load the downloaded version, possibly because they are based on the old version of Lama CPP. Instead, I developed a Deban Partition on the ROG and installed Olama to load and communicate with the GPT-OSS. If you want to follow the steps, I did the same with DPCAC at the beginning of the year. The error is that the performance is not localized enough, and there is no hardware acceleration, that is, you rely on the phone’s CPU for heavy lifting.
So, how well does the GPT-OSS Top Terry on Android smartphone? Barely is the word that I use. The ROG’s Snapdragon 8 Elite may be powerful, but it is nowhere near my laptop’s Snapdragon X, leaving a dedicated GPU for data cracking.
The GPT-OSS can only run on the phone, but it is barely usable.
The token rate (the rate at which the text is produced on the screen) is barely worth the passage and certainly slower than what I can read. I guess it is in the region of 2-3 tokens (one word or more) per second. This is not completely terrifying for short requests, but if you want to do something more complicated than you say hello it is painful. Unfortunately, as the size of your conversation increases, the token rate deteriorates, eventually it takes several minutes to produce some paragraphs.

Robert Triggs / Android Authority
Obviously, mobile CPUs are not really made for this type of work, and there are definitely not the model approaching that size. The ROG is a nipple actor for my daily workload, but because of this, there were about 100 % of the seven out of seven of the CPU core, which resulted in a few minutes after a few minutes of chat. The clock’s speed rotates quickly, which causes the token speed further. This is not very good.
With a model -filled model, 24GB of the phone was also extended, which requires OS, background apps, and immediate and demanded extra memory of answers and all reactions to the space. When I needed to go out in and out, I could, but already a slow token breed was brought to virtual style.
Another impressive model, but not for the phone
Calvin Wankheed / Android Authority
The question of running the GPT-SOS on your smartphone is much higher than the question, even if you have a huge Ram pond to load it. External models mainly do not support the mobile NPU and GPU. The only way around this barrier is to take advantage of the proprietary SD, such as Qualcomm AISD or Apple’s Core ML, for the developers, which will not be in case of such use.
Nevertheless, I was determined that equipped with GTX 1070 and 24GB of Ram, vowed to abandon and try the GPT-SOS on my elderly PC. The results were definitely better, four to five tokens per second, but still my Snapdragon was much slower than the X laptop that is only running on CPU -YEX.
In both cases, the 20B parameter version of the GPT-SOS is definitely inspired (after waiting for a while), thanks to the reasoning for its formation, which allows the model to help solve more complex issues, allowing the Langer to “think” for longer. Compared to free options like Google’s Gemini 2.5 Flash, GPT-OSS is solving the more capable problem thanks to China’s use, such as DiPsic R1, which is free, is the most impressive. However, it is still not as powerful as so powerful and more expensive cloud-based models-and certainly no user gadgets do so much more faster on any user gadget.
Nevertheless, advanced arguments in the palm of your hand, without cost, security concerns, or network compromises of today’s subscription models, the future of AI, I think laptops and smartphones should be truly aimed at making. Clearly, there is a long journey, especially when the mainstream hardware is a matter of access, but as the models both get smart and small, the future feels rapidly solid.
Some of my flagship smartphones have been reasonably expert in running small 8 billion parameter models like Kevin 2.5 and Lalma 3, with amazing and powerful results. If we ever see a speedy version of GPTOS, I will be more excited.
Thank you for being part of our community. Read our comment policy before posting.