

Photo by author
# Introduction
If you’re building applications with large language models (LLMs), you’ve probably experienced the scenario where you change the prompt, run it a few times, and the output feels better. But is it really better? Without objective metrics, you’re stuck with what the industry now calls “vibe testing,” which means making decisions based on intuition rather than data.
The challenge comes from a fundamental characteristic of AI models: uncertainty. Unlike traditional software, where the same input always produces the same output, LLMs can produce different responses to similar signals. This makes traditional unit testing ineffective and leaves developers wondering if their changes have actually improved performance.
Next came Google Stacks, a new experimentation toolkit. Google DeepMind And Google Labs AI is designed to bring accuracy to diagnosis. In this article, we take a look at how Stax enables developers and data scientists to evaluate models and prompts against their own custom criteria, replacing subjective judgments with repeatable, data-driven decisions.
# Understanding Google Stacks
Steaks is a developer tool that facilitates the evaluation of creative AI models and applications. Think of it as a testing framework built specifically for the unique challenges of working with LLMs.
At its core, Stax solves a simple but critical problem: How do you know if one model or prompt is better than another for your specific use case? Instead of relying on generic standards that may not reflect your application’s needs, Stax lets you define what “good” means for your project and measure against those standards.
// Finding key competencies
- It helps define your success criteria beyond general metrics like fluency and security.
- You can test different indicators in different models as well.
- You can make data-driven decisions by looking at aggregated performance metrics, including quality, latency, and token usage.
- It can run evaluations at scale using your own data sets.
Stax is flexible, not just supportive Google’s Gemini. Models rather OpenAI’s GPT, The anthropic cloud, Mistraland through other API integrations.
# Going beyond standard benchmarks
General AI benchmarks serve an important purpose, such as helping to track model progress at a high level. However, they often fail to reflect domain-specific needs. A model that excels at open-domain reasoning may perform poorly on specialized tasks such as:
- Summary focused on compliance
- Analysis of legal documents
- Enterprise-specific questions and answers
- Brand voice restriction
The difference between general benchmarks and real-world applications is where Stax provides value. This enables you to evaluate AI systems based on your data and your criteria, not abstract global scores.
# Getting Started with Stax
// Step 1: Adding an API Key
To generate model output and run diagnostics, you’ll need to add an API key. Stax recommends starting with one. Gemini API KeyAs the built-in evaluators use this by default, although you can configure them to use other models. You can add your first key during onboarding or later in settings.
To compare multiple providers, add keys for each model you want to test. This enables parallel comparisons without switching tools.
Obtaining an API key
// Step 2: Create an evaluation project
Projects are the central workspace in Stax. Each project corresponds to a single evaluation experiment, for example, testing a new system prompt or comparing two models.
You will choose from two project types:
| Type of project | Best for |
|---|---|
| Single model | Building a performance baseline or testing model or system prompt iteration |
| Side by side | Directly comparing two different models or benchmarking them head-to-head on the same dataset |

Figure 1: Flowchart of a side-by-side comparison showing two models that receive the same input prompts and their outputs go to an evaluator that produces a comparison matrix.
// Step 3: Creating Your Dataset
A solid evaluation starts with data that is accurate and reflects your real-world use cases. Stax offers two basic ways to achieve this:
Option A: Manually adding data to the prompt playground
If you don’t have an existing dataset, create one from scratch:
- Select the model you want to test.
- Set the system prompt (optional) to specify the role of the AI.
- Add user prompts that represent actual user input.
- Provide human ratings (optional) to create baseline quality scores.
Each input, output, and rating is automatically saved as a test case.
Option B: Upload an existing data set
For teams with production data, upload CSV files directly. If your dataset does not include model outputs, click “Generate Outputs” and select a model to generate them.
Best practice: Add edge cases and counterexamples to your dataset to ensure comprehensive testing.
# Assessing AI outputs
// Conducting manual assessment
You can provide human ratings on individual outputs directly on the playing field or on project benchmarks. While human assessment is considered the “gold standard,” it is slow, expensive, and difficult to scale.
// Autorating with Autoraters
To score multiple outputs simultaneously, Stax uses LL.M. as Judge Evaluation, where a powerful AI model evaluates the outputs of other models based on your criteria.
Stax includes preloaded evaluators for common metrics:
- Fluency
- Consistency of facts
- Safety
- The following instructions
- Comprehensiveness

The Stacks Evaluation interface displays a column of model outputs with adjacent score columns for different evaluations, as well as a “Run Evaluation” button.
// Leverage custom evaluators
While the preloaded evaluators provide a great starting point, building custom evaluators is the best way to measure what matters to your specific use case.
Custom evaluators let you define specific criteria such as:
- “Is the answer helpful but not overly familiar?”
- “Does the output contain personally identifiable information (PII)?”
- “Does the generated code follow our internal style guide?”
- “Does the brand voice fit our guidelines?”
To create a custom evaluator: Define your clear criteria, write a prompt for the judge model that includes a scoring checklist, and manually test it against a small sample of graded outputs to ensure alignment.
# Exploring practical use cases
// Examining Use Case 1: Customer Support Chatbot
Imagine you are building a customer support chatbot. Your needs may include the following:
- Professional tone
- Correct answers based on your knowledge
- No deception.
- Solution of common problems within three conversions
With Stax, you’ll:
- Upload a dataset of real customer queries.
- Generate responses from different models (or different instantiated versions).
- Create a custom evaluator that scores for professionalism and accuracy.
- Compare the results side by side to choose the best performer.
// Examining Use Case 2: Content Summarization Tool
To request a news summary, you should consider:
- Conciseness (summaries under 100 words)
- Compatibility of facts with the original article
- Protection of important information
Using Stax’s pre-built summarization quality evaluator gives you instant metrics, while custom evaluators can implement specific length constraints or brand sound requirements.
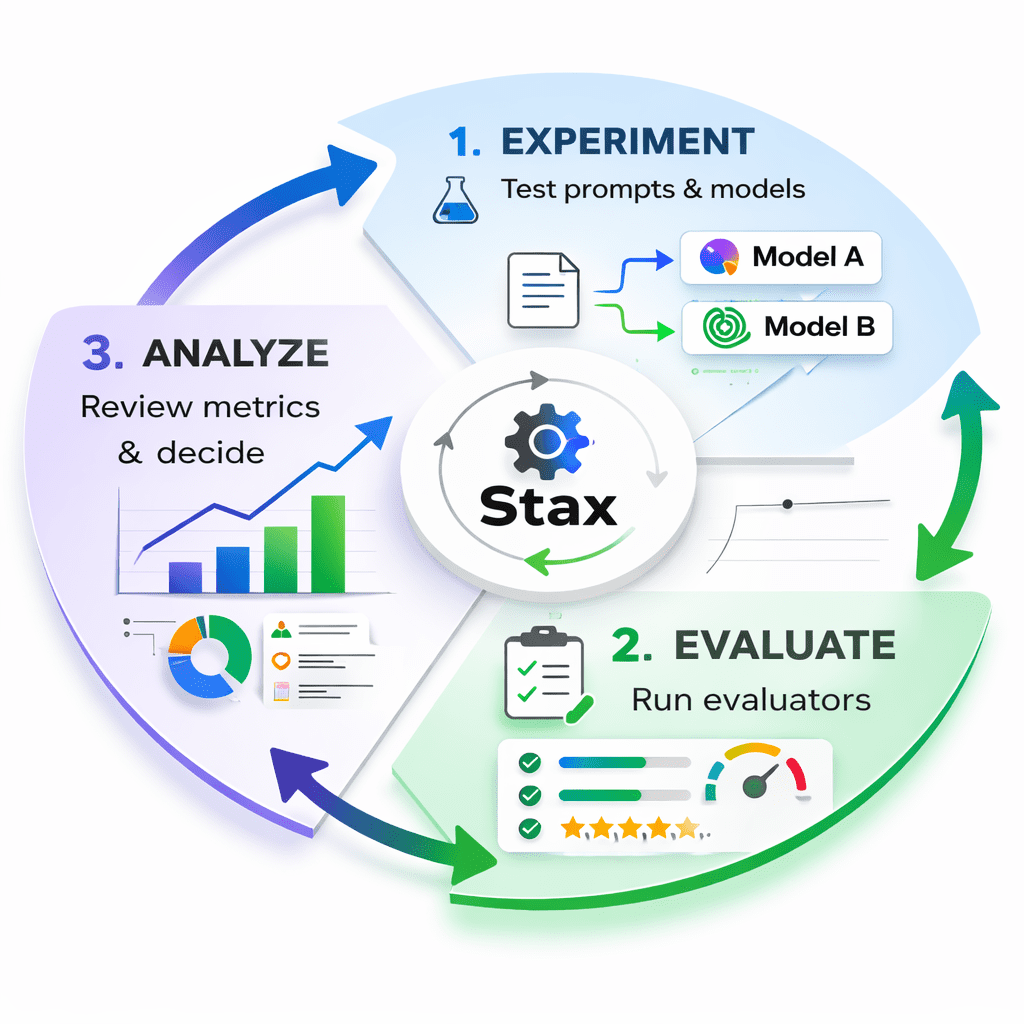
Figure 2: A visual of the Stax Flywheel showing the three stages: Experiment (test prompts/models), Evaluate (run analyzers), and Analyze (review metrics and make decisions)
# Interpreting the results
After the evaluation is complete, Stax adds new columns to your dataset showing the scores and arguments for each output. The Project Metrics section provides an overview of:
- Human classification
- Average evaluator scores
- Estimate delay
- Token count
Use this quantitative data:
- Compare repetitions: Does prompt A consistently improve prompt B?
- Choose between models: Is the faster model worth the slight drop in quality?
- Track progress: Is your optimization actually improving performance?
- Identify failures: Which inputs consistently produce poor outputs?

Figure 3: A dashboard view showing bar charts comparing two models across multiple metrics (quality score, latency, cost).
# Implementing best practices for effective evaluation
- Start small, then scale: You don’t need hundreds of test cases to get value. An assessment set with only ten high-quality prompts is more valuable than relying solely on vibe testing. Start with a focused set and expand as you learn.
- Create a regression test: Your assessment should include tests that protect the current standard. For example, “Always output valid JSON” or “Never include competing names.” These prevent new changes from breaking things that already work.
- Create a challenge set: Create datasets targeting areas where you want to improve your AI. If your model struggles with complex reasoning, set a challenge specifically for that ability.
- Don’t give up on human review: While automated evaluations scale better, getting your team to use your AI product is critical to generating insights. Use Stax to capture compelling examples from human testing and add them to your formal evaluation datasets.
# Answering frequently asked questions
- What is Google STAX? Stax is a developer tool from Google for evaluating applications powered by LLM. It helps you test models and indicators against your own criteria rather than relying on generic standards.
- How does Stax AI work? Stax uses an “LLM-as-judge” approach where you define evaluation criteria, and an AI model scores the output based on those criteria. You can use pre-built evaluators or create your own.
- Which Google tool allows people to build their own machine learning models? While Stax focuses on evaluation rather than model building, it works with other Google AI tools. To build and train models, you’ll typically use TensorFlow or Vertex AI. Stax then helps you evaluate the performance of these models.
- What is Google Chat equivalent to GPT? Google’s primary conversational AI is Gemini (formerly Bard). Stax can help you test and optimize prompts for Gemini and compare its performance to other models.
- Can I train AI on my data? Stax does not train models. It evaluates them. However, you can use your data as test cases to evaluate pre-trained models. To train custom models on your data, you’ll use tools like Vertex AI.
# The result
The era of Vibe testing is coming to an end. As AI moves from experimental demos to production systems, detailed evaluation becomes critical. Google Stax provides the framework for defining what “good” means for your unique use case and the tools to systematically measure it.
By replacing subjective judgments with repeatable, data-driven assessments, Stax helps you:
- Send AI features with confidence.
- Make informed decisions about model selection.
- Repeat quickly on prompts and system instructions.
- Build AI products that reliably meet user needs.
Whether you’re a beginning data scientist or a seasoned ML engineer, adopting structured assessment methods is how you build with AI. Start small, define what matters to your application, and let the data guide your decisions.
Ready to move beyond vibe testing? visit stax.withgoogle.com To explore the tool and join the community of developers building better AI applications.
// References
Shatu Olomide A software engineer and technical writer with a knack for simplifying complex concepts and a keen eye for detail, passionate about leveraging modern technology to craft compelling narratives. You can also search on Shittu. Twitter.