

In this tutorial, you’ll build a production-ready voice agent architecture: a browser client that streams audio over WebRTC (Web Real-Time Communication), a backend that issues short-lived session tokens, an agent runtime that securely orchestrates speech and tools, and prototyping post-call workflows.
This article is intentionally vendor neutral. You can implement these patterns using any AI voice platform that supports WebRTC (directly or via SFU, the Selective Forwarding Unit) and server-side token minting. The goal is to help you ship a voice agent architecture that is secure, observable, and executable in production.
Disclosure: This article reflects my personal views and experience. It does not represent the views of my employer or any vendor mentioned.
Table of Contents
What will you make?
By the end, you will have:
A web client that streams microphone audio and plays agent audio.
A backend token endpoint that holds credentials server-side.
A secure coordination channel between the agent and the application.
Structured messages between the application and the agent.
A production checklist for security, reliability, observability, and cost control.
Conditions
You should be comfortable with:
JavaScript or TypeScript
Node.js 18+ (so
fetchworks on the server side) and an HTTP framework (express in examples)Browser microphone permissions.
Basic WebRTC concepts (high level is fine)
TL; DR
Oh Production-ready voice agent Requirements:
Oh Server-side token service (no secrets in the browser)
Oh Real-time media plane (WebRTC) for low-latency audio
Oh Data channel For managed messages between your app and the agent
Instrument stations (permission lists, authentications, timeouts, audit logs)
Post-call action (Summary, Actions, CRM (Customer Relationship Management), Tickets)
Observation – First Implementation (state transition + matrix)
How to Avoid Common Production Failures in Voice Agents
If you’ve run distributed systems, you’ve noticed that most failures occur within the boundaries of:
Timeout and partial connection
Retries which increase the load.
Implicit ownership between components
Lack of observation
“Assistant Automation” that becomes unsafe.
Acoustic agents increase these risks because:
Latency is the user experience.: A lazy agent feels broken. Conversational UX is less forgiving than web UX.
Audio + UI + Tools is a distributed system.: You integrate browser audio capture, WebRTC transport, STT (speech-to-text), model reasoning, tool calls, TTS (text-to-speech) and playback buffering. Each phase has different clocks and failure modes.
Safety boundaries are non-negotiable.: A leaked API key is catastrophic. A tool misfire can trigger real-world side effects.
Debugability determines whether you can ship.: If you don’t log state transitions and get post-call samples, you can’t run or optimize the system safely.
How to design a latency budget for a real-time voice agent.

Communication has a “feel”. This feeling is often delayed.
A practical guideline:
Your end-to-end latency is a combination of mic capture, network RTT (round trip time), STT, reasoning, tool execution, TTS, and playback buffering. Budget for this clearly or you’ll ship a technically sound system that users find unintelligent.
How to Design a Production Voice Agent Architecture (Vendor Neutral)
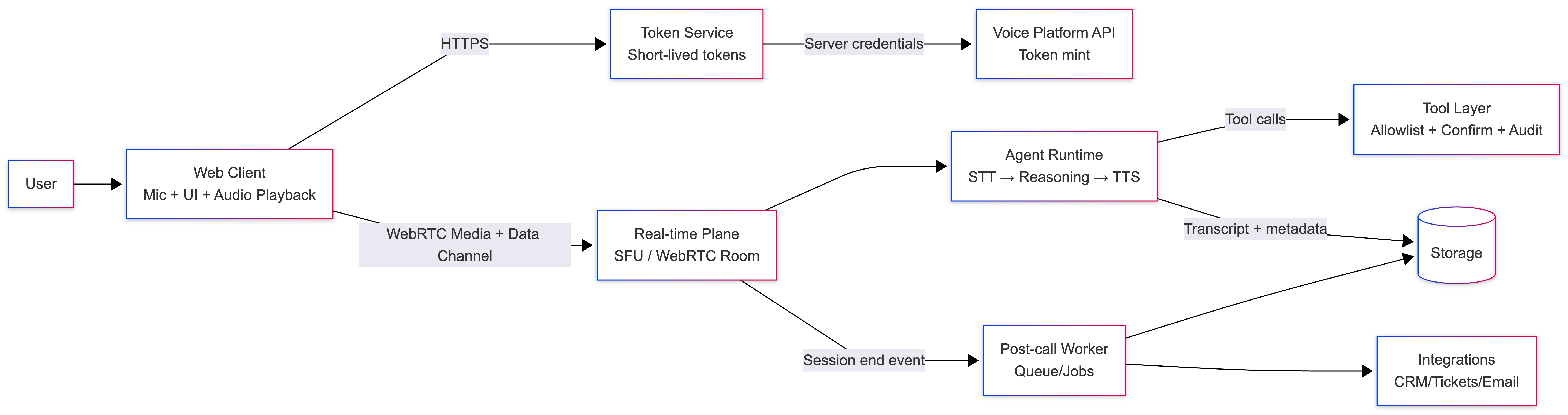
An expandable Acoustic agent architecture Generally these layers are:
Web client: Mic capture, audio playback, UI state
Token service: short-lived session token (secrets remain server-side)
Real time aircraft: WebRTC media + a data channel
Agent runtime: STT → Reasoning → TTS, plus tool orchestration
Tool layer: External operations behind security controls
Post call processor: Summary + structured output after the session ends
This separation defines failure domains and confidence limits.
Step 0: Set up the project.
Create a new project directory:
mkdir voice-agent-app
cd voice-agent-app
npm init -y
npm pkg set type=module
npm pkg set scripts.start="node server.js"
Install dependencies:
npm install express dotenv
Create this folder structure:
voice-agent-app/
├── server.js
├── .env
└── public/
├── index.html
└── client.js
add .env file:
VOICE_PLATFORM_URL=
VOICE_PLATFORM_API_KEY=your_api_key_here
Now you are ready to implement each part of the system.
Step 1: Put the credentials on the server side
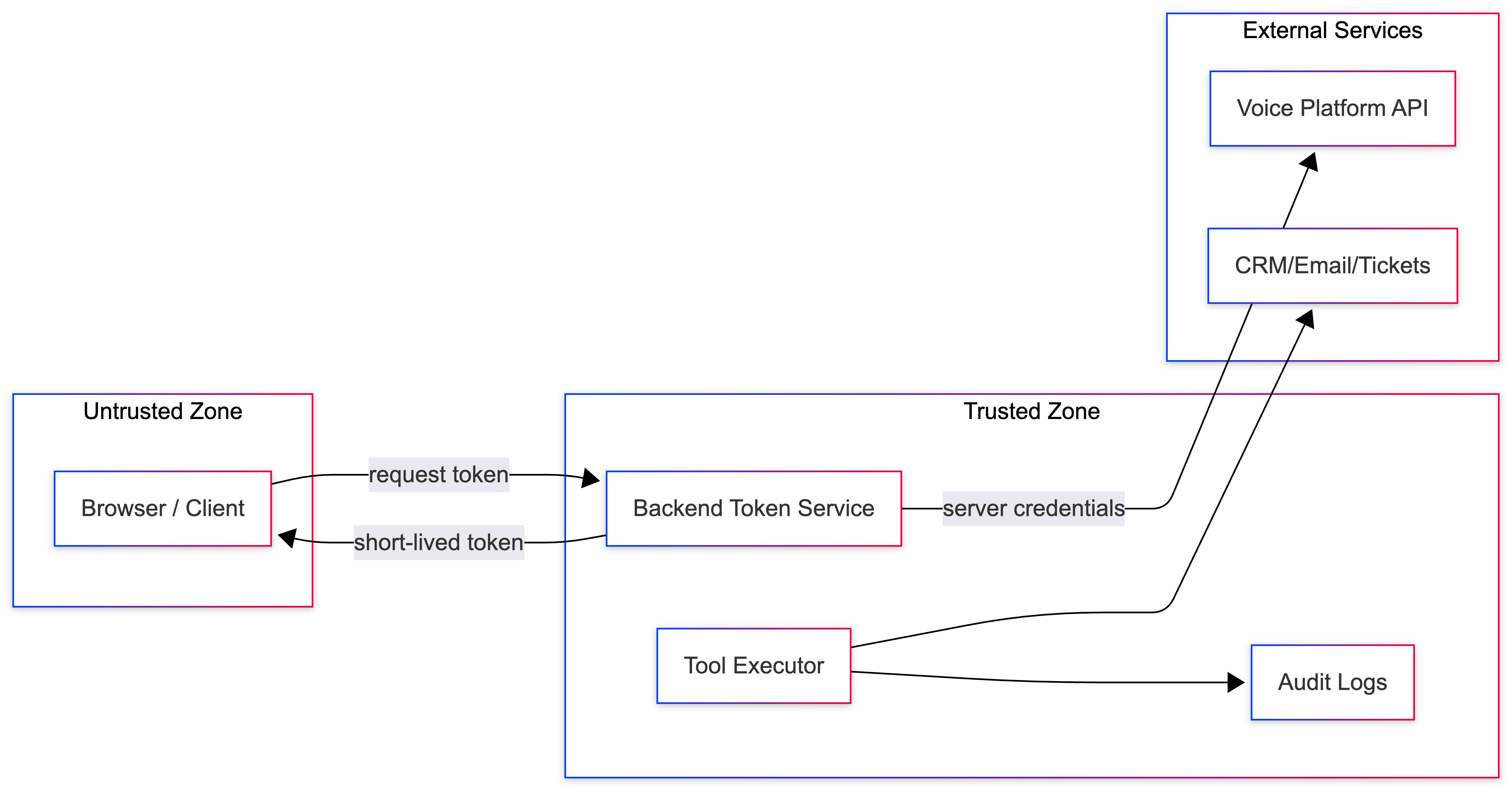
Treat each API key like a production credential:
Save it in Environment Variables or Secrets Manager.
If exposed, rotate it
Never embed it in browsers or mobile apps.
Avoid logging secrets (only log a short suffix if necessary)
Even if a vendor supports CORS, the browser is not a secure place for long-lived credentials.
Step 2: Create a backend token endpoint
Your background should be:
Create server.js (Node.js + Express)
import express from "express";
import dotenv from "dotenv";
import path from "path";
import
rtc_url: data.rtc_url from "url";
dotenv.config();
const app = express();
app.use(express.json());
// Serve the web client from /public
const __filename = fileURLToPath(import.meta.url);
const __dirname = path.dirname(__filename);
app.use(express.static(path.join(__dirname, "public")));
const VOICE_PLATFORM_URL = process.env.VOICE_PLATFORM_URL;
const VOICE_PLATFORM_API_KEY = process.env.VOICE_PLATFORM_API_KEY;
app.post("/api/voice-token", async (req, res) => {
res.setHeader("Cache-Control", "no-store");
try
if (!VOICE_PLATFORM_URL catch (err) res.status
});
app.listen(3000, () => console.log("Open
Run the server.
npm start
How does this code work?
You load the credentials from environment variables so that the secrets are never leaked to the browser.
gave
/api/voice-tokenThe endpoint calls the token API of the voice platform.Just back to you
rtc_url,tokenand the expiration time.The browser never sees the API key.
If the provider returns an error, you forward a structured error response.
Production Notes
Rate limit /api/voice-token (cost + abuse control)
Instrument token minute latency and error rate
Keep TTL short and handle refresh/reconnect.
Return the minimum number of fields.
Step 3: Connect to Web Client (WebRTC + SFU)
In this step, you’ll create a minimal web UI that:
Requests a short-term token from your backend.
Real-time WebRTC connects to the room (usually via SFU).
Plays the agent’s audio track.
A microphone captures and publishes audio.
make public/index.html
Voice Agent Demo
Idle
make public/client.js
Note: This uses a LiveKit-style client SDK to expose patterns. If you are using a different provider, change this import and the connect/publish calls to your provider's WebRTC client.
import "Connection failed");
startBtn.disabled = false;
endBtn.disabled = true;
room = null;
detachAllAudio();
from "
const startBtn = document.getElementById("startBtn");
const endBtn = document.getElementById("endBtn");
const statusEl = document.getElementById("status");
let room = null;
let intentionallyDisconnected = false;
let audioEls = ();
function setStatus(text)
function detachAllAudio() {
for (const el of audioEls) {
try { el.pause?.(); } catch {}
el.remove();
}
audioEls = ();
}
async function mintToken() {
const res = await fetch("/api/voice-token", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ participant_name: "Web User" }),
cache: "no-store",
});
if (!res.ok) {
const detail = await res.text().catch(() => "");
throw new Error(`Token request failed: ${detail || res.status}`);
}
const { rtc_url, token } = await res.json();
if (!rtc_url || !token) throw new Error("Token response missing rtc_url or token");
return { rtc_url, token };
}
function wireRoomEvents(r) {
// 1) Play the agent audio track when subscribed
r.on(RoomEvent.TrackSubscribed, (track) => {
if (track.kind !== Track.Kind.Audio) return;
const el = track.attach();
audioEls.push(el);
document.body.appendChild(el);
// Autoplay restrictions vary by browser/device.
el.play?.().catch(() => {
setStatus("Connected (audio may be blocked — click the page to enable)");
});
});
// 2) Reconnect on disconnect (token expiry often shows up this way)
r.on(RoomEvent.Disconnected, async () => {
if (intentionallyDisconnected) return;
setStatus("Disconnected (reconnecting...)");
await attemptReconnect();
});
}
async function connectOnce() {
const { rtc_url, token } = await mintToken();
const r = new Room();
wireRoomEvents(r);
await r.connect(rtc_url, token);
// Mic permission + publish mic
try {
await r.localParticipant.setMicrophoneEnabled(true);
} catch {
try { r.disconnect(); } catch {}
throw new Error("Microphone access denied. Allow mic permission and try again.");
}
return r;
}
async function startCall() {
if (room) return;
intentionallyDisconnected = false;
setStatus("Connecting...");
room = await connectOnce();
setStatus("Connected");
startBtn.disabled = true;
endBtn.disabled = false;
}
async function stopCall() {
intentionallyDisconnected = true;
try {
await room?.localParticipant?.setMicrophoneEnabled(false);
} catch {}
try {
room?.disconnect();
} catch {}
room = null;
detachAllAudio();
setStatus("Disconnected");
startBtn.disabled = false;
endBtn.disabled = true;
}
async function attemptReconnect() {
// Simplified exponential backoff reconnect.
// In production, add jitter, max attempts, and better error classification.
const delaysMs = (250, 500, 1000, 2000);
for (const delay of delaysMs) {
if (intentionallyDisconnected) return;
try {
// Tear down current state before reconnecting
try { room?.disconnect(); } catch {}
room = null;
detachAllAudio();
await new Promise((r) => setTimeout(r, delay));
room = await connectOnce();
setStatus("Reconnected");
startBtn.disabled = true;
endBtn.disabled = false;
return;
} catch {
// keep retrying
}
}
setStatus("Disconnected (reconnect failed)");
startBtn.disabled = false;
endBtn.disabled = true;
}
startBtn.addEventListener("click", async () => {
try {
await startCall();
} catch (err) {
setStatus(err?.message || "Connection failed");
startBtn.disabled = false;
endBtn.disabled = true;
room = null;
detachAllAudio();
}
});
endBtn.addEventListener("click", async () => {
await stopCall();
});
How this step works (and why these details are important)
-
The Start button gives you a user prompt so browsers are more likely to allow audio playback.
-
Mic permission is handled implicitly: if the user denies access, you display an explicit error and avoid a half-connected session.
-
Disconnect cleanup removes audio elements so you don't leak resources on retries.
-
The reconnect loop reflects the production pattern: if a connection is lost (often due to token expiration or a network crash), the client re-mints a token and reconnects.
In the next step, you'll add a managed data channel handler to securely process the "client actions" suggested by the agent.
Handle them clearly.
An example of an autoplay restriction
Add to it. index.html:
i client.js:
const startBtn = document.getElementById("startBtn");
const endBtn = document.getElementById("endBtn");
const statusEl = document.getElementById("status");
let room;
startBtn.addEventListener("click", async () => {
try {
room = await connectVoice();
statusEl.textContent = "Connected";
startBtn.disabled = true;
endBtn.disabled = false;
} catch (err) {
statusEl.textContent = "Connection failed";
}
});
Refuse the microphone
try {
await navigator.mediaDevices.getUserMedia({ audio: true });
} catch (err) {
statusEl.textContent = "Microphone access denied";
throw err;
}
Discontinue cleaning.
endBtn.addEventListener("click", () => {
if (room) {
room.disconnect();
statusEl.textContent = "Disconnected";
startBtn.disabled = false;
endBtn.disabled = true;
}
});
Token refresh (easy)
room.on(RoomEvent.Disconnected, async () => {
const res = await fetch("/api/voice-token");
const { rtc_url, token } = await res.json();
await room.connect(rtc_url, token);
});
Step 4: Add client actions (agent suggestions, app completion)
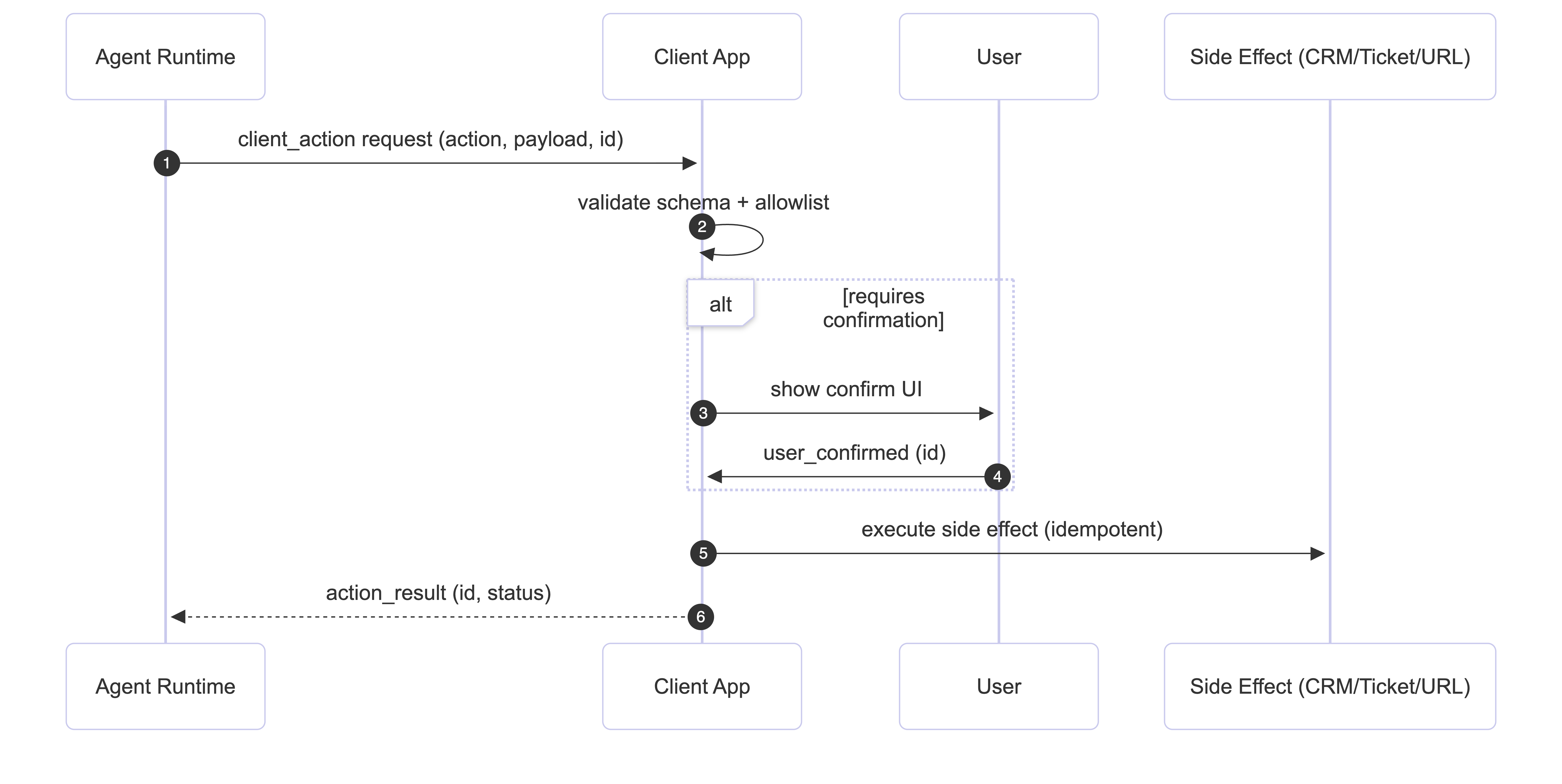
A production voice agent often needs to:
-
Open the runbook/dashboard URL.
-
Show checklist in UI.
-
Request confirmation for irreversible processing.
-
Get structured context (account, region, event ID)
Important safety rules:
The agent recommends actions. The application validates and implements them.
Use structured messages over a data channel:
{
"type": "client_action",
"action": "open_url",
"payload": { "url": " },
"id": "action_123"
}
Add guardrails.:
-
List of allowed actions
-
Validate the format of the payload.
-
Authentication gates for irreversible actions
-
Idempotency by ID
-
Audit logs for each request and results
This limit limits the damage caused by a decoy or quick injection.
// Guardrails: allowlist + validation + idempotency + confirmation
const ALLOWED_ACTIONS = new Set(("open_url", "request_confirm"));
const EXECUTED_ACTION_IDS = new Set();
const ALLOWED_HOSTS = new Set(("internal.example.com"));
function parseClientAction(text) {
let msg;
try {
msg = JSON.parse(text);
} catch {
return null;
}
if (msg?.type !== "client_action") return null;
if (typeof msg.id !== "string") return null;
if (!ALLOWED_ACTIONS.has(msg.action)) return null;
return msg;
}
async function handleClientAction(msg, room) {
if (EXECUTED_ACTION_IDS.has(msg.id)) return; // idempotency
EXECUTED_ACTION_IDS.add(msg.id);
console.log("(client_action)", msg); // audit log (demo)
if (msg.action === "open_url") {
const url = msg.payload?.url;
if (typeof url !== "string") return;
const u = new URL(url);
if (!ALLOWED_HOSTS.has(u.host)) {
console.warn("Blocked navigation to:", u.host);
return;
}
window.open(url, "_blank", "noopener,noreferrer");
return;
}
if (msg.action === "request_confirm") {
const prompt = msg.payload?.prompt || "Confirm this action?";
const ok = window.confirm(prompt);
// Send confirmation back to agent/app
room.localParticipant.publishData(
new TextEncoder().encode(
JSON.stringify({ type: "user_confirmed", id: msg.id, ok })
),
{ topic: "client_events", reliable: true }
);
}
}
room.on(RoomEvent.DataReceived, (payload, participant, kind, topic) => {
if (topic !== "client_actions") return;
const text = new TextDecoder().decode(payload);
const msg = parseClientAction(text);
if (!msg) return;
handleClientAction(msg, room);
});
Step 5: Add tool integration securely.
Tools turn voice agents into automation. Regardless of the seller, apply these rules:
-
Timeout on each tool call
-
Circuit breaker for flaky dependence
-
Audit logs (input, output, duration, trace ID)
-
Clear confirmation of destructive operations
-
Credentials are stored on the server side (never in the prompts or clients).
Fall back gracefully if tools fail ("I can't access this system right now, there's a manual fallback."). Silence reads as failure.
Create a server-side tool runner (example)
Paste it in. server.js:
const TOOL_ALLOWLIST = {
get_status: { destructive: false },
create_ticket: { destructive: true },
};
let failures = 0;
let circuitOpenUntil = 0;
function circuitOpen() {
return Date.now() < circuitOpenUntil;
}
async function withTimeout(promise, ms) {
return Promise.race((
promise,
new Promise((_, reject) => setTimeout(() => reject(new Error("timeout")), ms)),
));
}
async function runToolSafely(tool, args) {
if (circuitOpen()) throw new Error("circuit_open");
try {
const result = await withTimeout(Promise.resolve({ ok: true, tool, args }), 2000);
failures = 0;
return result;
} catch (err) {
failures++;
if (failures >= 3) circuitOpenUntil = Date.now() + 10_000;
throw err;
}
}
app.post("/api/tools/run", async (req, res) => {
const { tool, args, user_confirmed } = req.body || {};
if (!TOOL_ALLOWLIST(tool)) return res.status(400).json({ error: "Tool not allowed" });
if (TOOL_ALLOWLIST(tool).destructive && user_confirmed !== true) {
return res.status(400).json({ error: "Confirmation required" });
}
try {
const started = Date.now();
const result = await runToolSafely(tool, args);
console.log("(tool_call)", { tool, ms: Date.now() - started }); // audit log
res.json({ ok: true, result });
} catch (err) {
console.log("(tool_error)", { tool, err: String(err) });
res.status(500).json({ ok: false, error: "Tool call failed" });
}
});
Step 6: Add post-call processing (where persistent value appears)

After the call ends, generate the structure sample:
Production pattern:
-
Store transcript + metadata.
-
Queue a background job (queue/worker)
-
Generate output as JSON + a human-readable report.
-
Apply integration with retries + idempotency.
-
Store "Call Report" for audit and incident reviews.
Create a post call webhook endpoint (example)
paste in server.js:
app.post("/webhooks/call-ended", async (req, res) => {
const payload = req.body;
console.log("(call_ended)", {
call_id: payload.call_id,
ended_at: payload.ended_at,
});
setImmediate(() => processPostCall(payload));
res.json({ ok: true });
});
function processPostCall(payload) {
const transcript = payload.transcript || ();
const summary = transcript.slice(0, 3).map(t => `- \({t.speaker}: \){t.text}`).join("\n");
const report = {
call_id: payload.call_id,
summary,
action_items: payload.action_items || (),
created_at: new Date().toISOString(),
};
console.log("(call_report)", report);
}
Check it locally.
curl -X POST /webhooks/call-ended \
-H "Content-Type: application/json" \
-d '{
"call_id": "call_123",
"ended_at": "2026-02-26T00:10:00Z",
"transcript": (
{"speaker": "user", "text": "I need help resetting my password."},
{"speaker": "agent", "text": "Sure — I can help with that."}
),
"action_items": ("Send password reset link", "Verify account email")
}'
Production preparation list
Security
-
There are no API keys in the browser.
-
Strict permission list for client actions
-
Authentication gates for destructive operations
-
Schema validation on all inbound messages
-
Audit logging for actions and tool calls
Reliability
-
Reintegrated strategy for expired tokens
-
Timeout + circuit breaker for tools
-
Graceful degradation when dependencies fail
-
idempotent side effects
observation
Log state transitions (for example):
Listening → Thinking → Speaking → Finished.
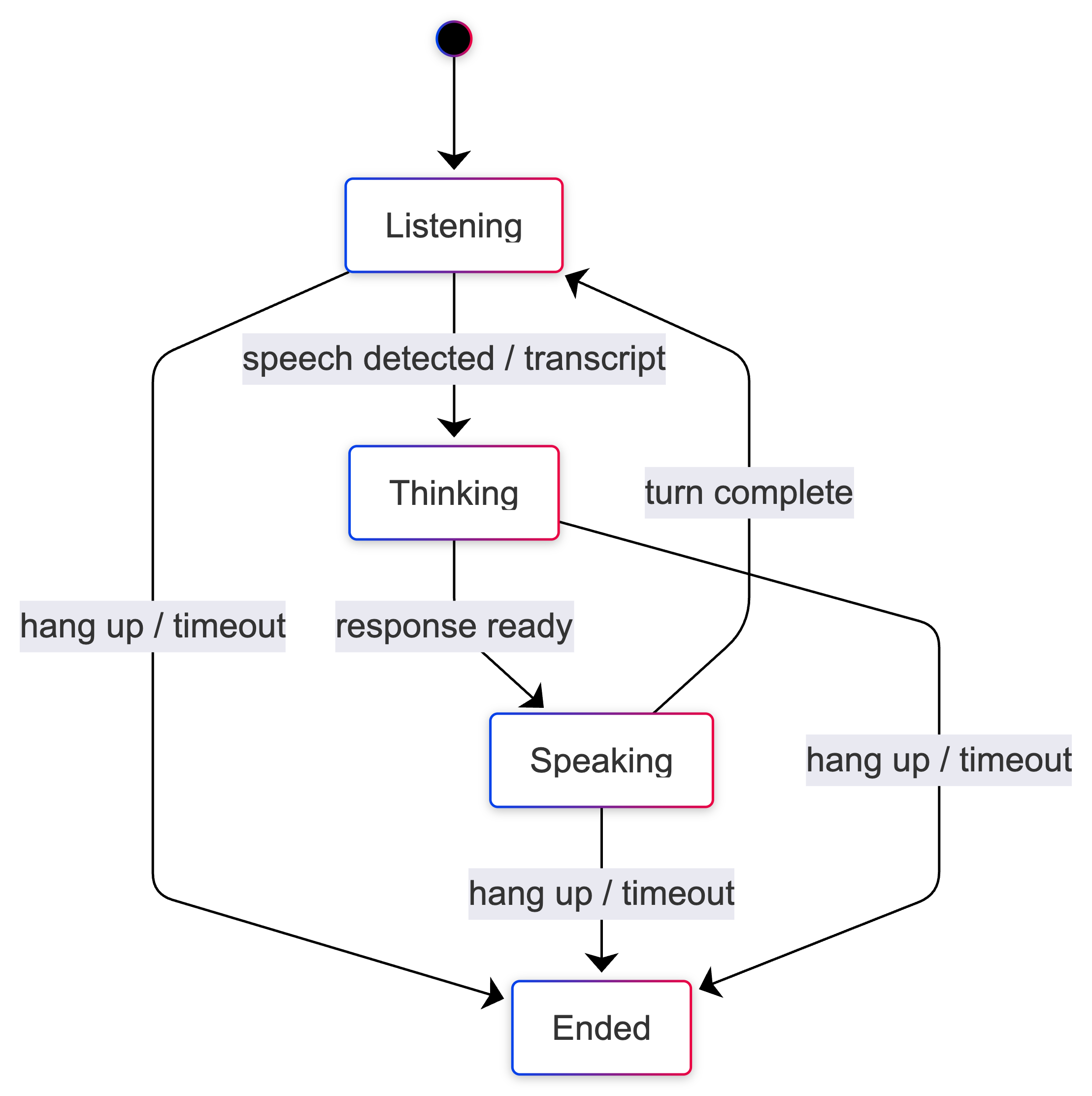
track:
Cost control
-
Rate limit token minting and session
-
Cap maximum call duration
-
Development of bounded context (abstraction or shortening)
-
Track Per Call Usage Driver (STT/TTS Minutes, Toll Calls)
Optional resources
How to quickly test a managed voice platform
If you'd like an early check from a regulated provider, you can sign up for one. Vocal bridge account And implement these steps using their token minting + real-time session APIs.
But the underlying production voice agent architecture in this article is vendor-agnostic. You can replace any component (SFU, STT/TTS, agent runtime, tool layer) as long as you preserve the boundaries: secure token service, real-time media, secure tool execution, and robust observation.
See a full demo and explore a complete reference repo.
If you want to see these patterns working together in a realistic scenario (incident triage), here are two optional resources:
- Demo video: Voice-first incident triage (end-to-end)
This is a hackathon run-through showing client actions, decision boundaries for irreversible actions, and a structured post-call summary.
- GitHub Repo (Architecture + Design + Working Code):
These links are optional, you can follow the tutorial end-to-end without them.
to close
Production-ready voice agents work when you treat them like real-time distributed systems.
Start with a baseline:
- Token Service + Web Client + Realtime Audio
Then layer in:
This is how you ship a voice agent architecture that you can run. You now have a vendor-neutral reference architecture that you can adapt to your stack with clear trust boundaries, secure tool execution and operational visibility.
If you're shipping real-time AI systems, what's your biggest production bottleneck so far: Latency, reliability, or security of the device? I'd love to hear what you're seeing in the wild. contact me LinkedIn.