
Want a smart insight into your inbox? Sign up for our weekly newsletters to get the only thing that is important to enterprise AI, data, and security leaders. Subscribe now
False Today issued an open -open acoustic model that can compete with paid voice AI, as these people Eleven lobes And AlwaysWhich the company has said that proprietary speech identification models and more open, still bridges the distance between the error -affected version.
Vocabral, which will be released under the Mr. Apache 2.0 License, is available in 24B parameter version and 3B different types. The big model is aimed at scale applications, while the smaller version will work for local and edge use matters.
“Voice was the first interface of humanity-long before writing or typing, so we share ideas, harmonize work and build relationships. Since the digital system is more capable, the sound is returning as our most natural form of human computer conversation.” Blog Post. “Despite this, today’s systems are limited-unnecessary, proprietary, and the use of the real world very easily.
Vocabral Mr. API and only one transcript is available on the closing point on his website. Models are also accessible through Mr’s chat platform, Lee Chat.
AI Impact Series returning to San Francisco – August 5
The next step of the AI is here – are you ready? Block, GSK, and SAP leaders include for a special look on how autonomous agents are changing enterprise workflows-from real time decision-making to end to automation.
Now secure your place – space is limited:
Mr said that speech AI means “choosing between two commercial relations,” pointing that some open source automatic speech identification models are often limited. Nevertheless, closed models with strong language understanding come at a higher price.
To bed the space
The company said that the Voccusal “offers the latest accuracy and local term understanding at less than half the price of the comparative API.”
Vocabral, 32K tokens can hear and copy audio understanding for 30 minutes, for 30 minutes or for 40 minutes. It offers a summary, which means that the model can answer questions based on audio content and create a summary without switching to a separate mode. Customers can mobilize functions and API calls based on the guidelines.
This model is based on Mr. Mistles’ misunderstanding small 3.1. It supports multiple languages and can automatically detect languages like English, Spanish, French, Portuguese, Hindi, German, Italian and Dutch.
Mr. included the characteristics of the enterprise in the Vocabral, including private deployment, so that organizations could integrate the model into their ecosystem. These features include domain -related toning and sophisticated contexts and preferred access to engineering resources for users who need to help Voccusal integrate into their workflose.
Efficiency
The identity of the speech is available on many platforms today. Consumers can talk to Chat GPT, and the platform will take action on speaking instructions like written gestures. Fast food chains such as White Castle have been deployed Sound Hound Their drive throw services, and eleven labs have permanently improved their multi -modal platform. Open source also offers powerful powers. Nari LabsA Startup, in April, the Open Source Speech Model Dia. However, some of these services can be expensive.
Such as Transcript Services Authot And Read.Ai Now you can inform yourself of zoom meetings, recording, summarizing and even consumers. Many online video meeting platforms not only offer duplicate, but also present with speech AI and agent AI Google Meetings providing notes for Gemini users. As a regular user of Voice Transcript Services, I can say myself that the identity of the speech is not perfect, but it is improving.
Mr. said Woccusal improved the current voice model, including Open IAuthor from Gemini 2.5 Flash and eleven labs. Vocabral presented less words mistakes than whispers, which are currently considered to be the best automatic speech identification model available.
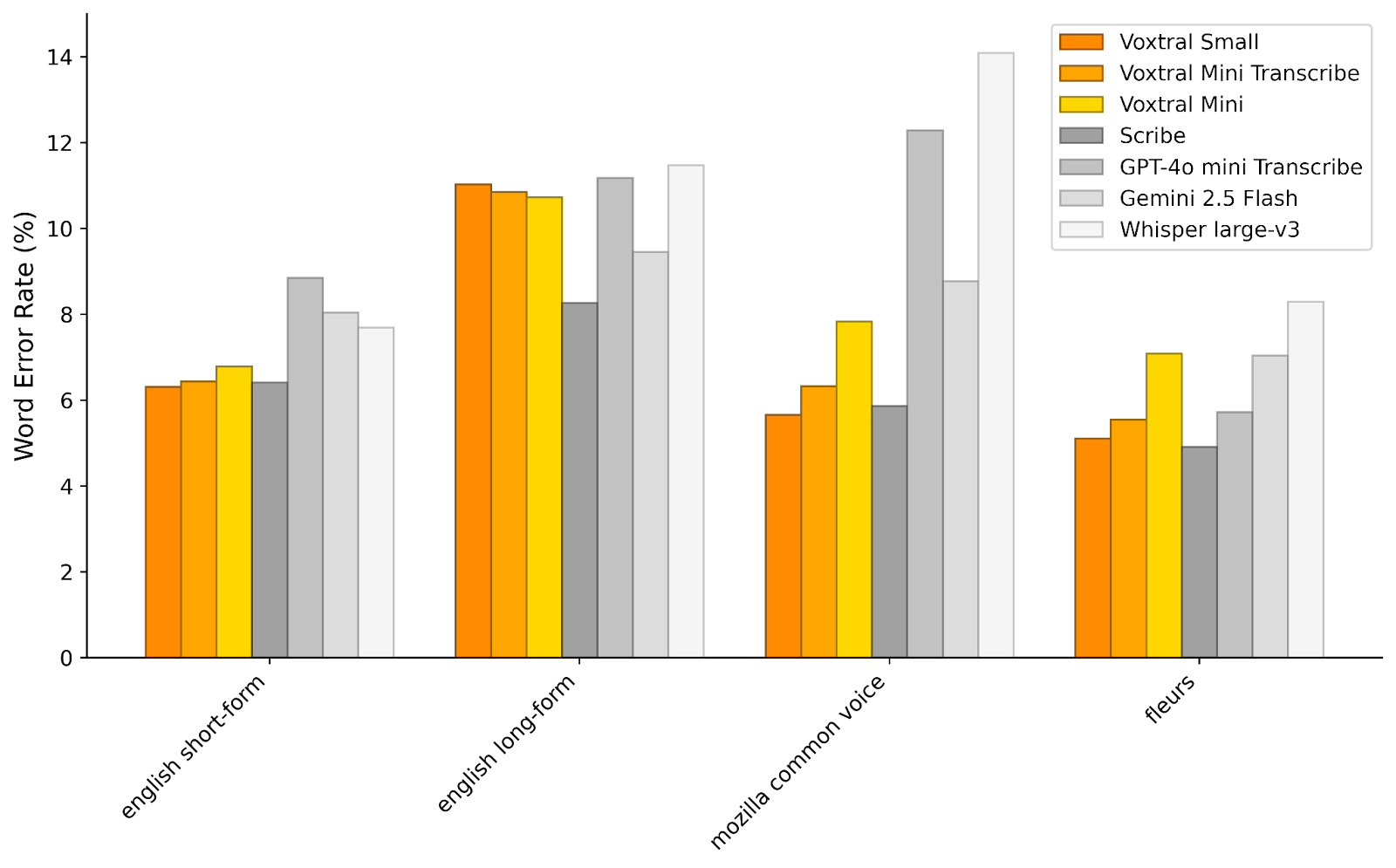
In the case of audio understanding, Vocabral Small is competitive with GPT-4O-Mini and Gemini 2.5 flash in all tasks, gaining sophisticated performance in speech translation. “
Since announcing Vocabral, social media users have said they have been waiting for an open source speech model that can be similar to the performance of the whisper.
Mr. said that Voccusal would be available through his API at 00 0.001 per minute.
