


Photo by author
# Introduction
When you’ve solved enough interview-style data problems, you start to notice a funny effect: the dataset “shape” quietly dictates your coding style. The time series table will direct you to the window functions. A star schema pushes you to join chains and group BY. Oh Pandey Working with two data frames requires approx. .merge() And isin().
This article makes that intuition measurable. Using a set of representative SQL and Pandas problems, we will identify key code structure features (use of Common Table Expressions (CTE), frequency of window functions, common Pandas techniques) and illustrate which elements are dominant and the reasons behind them.
![]()
# Why Data Structures Change Your Coding Style
Rather than just logic, data problems are like constraints wrapped in tables:
// Rows that depend on other rows (time, status, “previous value”)
If the answer for each row depends on adjacent rows (eg yesterday’s temperature, previous transactions, running totals), solutions naturally lean towards window functions e.g. LAG(), LEAD(), ROW_NUMBER()and DENSE_RANK().
Consider this for example. Interview Questions Tables:
![]()
The result of each user on a given day cannot be determined in isolation. After totaling order costs at the customer day level, each row must be evaluated against other customers on the same date to determine which total is the highest.
![]()
Since the response of a row depends on how it ranks relative to its peers within the time distribution, the shape of the data set naturally leads to window functions such as RANK() or DENSE_RANK() Instead of simple plurals alone.
// Multiple tables with characters (dimensions vs facts)
When one table defines entities, and another defines events, the solution is the JOIN + GROUP BY pattern (SQL) or .merge() + .groupby() pattern (panda)
For example, in this Interview questionthe data table is as follows:
![]()
![]()
![]()
In this example, since entity attributes (users and account status) and event data (downloads) are separate, the logic must first rejoin them using JOINs before meaningful aggregation (absolute dimensions) can occur. This is the fact pattern that creates a JOIN + GROUP BY solution.
// Small Outputs with Output Logic (Anti-Join Patterns)
Problems asking “who has never done X” often become left joins… IS NULL / NOT EXISTS (SQL) or ~df('col').isin(...) (Panda).
# What we measure: Characteristics of code structure
To compare “coding styles” across different solutions, it is useful to identify a limited set of observable characteristics that can be extracted from SQL text and Python code.
While these may not be perfect indicators of solution quality (e.g., accuracy or efficiency), they can serve as reliable signals regarding how analysts engage with the dataset.
// The SQL properties we measure.
![]()
// Characteristics of pandas we measure
![]()
# Which constructions are most common?
To move beyond anecdotal observations and quantify these patterns, you need a more straightforward and consistent method to obtain structural signals directly from the solution code.
As a solid anchor for this workflow, we used all of the academic questions. StrataScratch The platform
In the result shown below, “Total Occurrence” is the raw count of occurrences of the pattern across all code. A query solution can use JOIN 3 times, so all 3 are combined. “Queries using” refers to how many distinct queries have at least one occurrence of that feature (ie, one binary “used/not used” per query).
This method reduces each solution to a limited set of observable features, enabling us to consistently and reproducibly compare coding estimates between problems and to directly relate dataset structure to dominant constructs.
// Features of SQL
![]()
// Features of Pandas (Python Solutions)
![]()
// Feature extraction code
Below, we present the code snippets used, which you can use on your solution (or rephrase the answers in your own terms) and extract features from the code text.
// SQL Feature Extraction (Example)
import re
from collections import Counter
sql = # insert code here
SQL_FEATURES = {
"cte": r"\bWITH\b",
"join": r"\bJOIN\b",
"group_by": r"\bGROUP\s+BY\b",
"window_over": r"\bOVER\s*\(",
"dense_rank": r"\bDENSE_RANK\b",
"row_number": r"\bROW_NUMBER\b",
"lag": r"\bLAG\b",
"lead": r"\bLEAD\b",
"not_exists": r"\bNOT\s+EXISTS\b",
}
def extract_sql_features(sql: str) -> Counter:
sql_u = sql.upper()
return Counter({k: len(re.findall(p, sql_u)) for k, p in SQL_FEATURES.items()})// Pandas Feature Extraction (Example)
import re
from collections import Counter
pandas = # paste code here
PD_FEATURES = {
"merge": r"\.merge\s*\(",
"groupby": r"\.groupby\s*\(",
"rank": r"\.rank\s*\(",
"isin": r"\.isin\s*\(",
"sort_values": r"\.sort_values\s*\(",
"drop_duplicates": r"\.drop_duplicates\s*\(",
"transform": r"\.transform\s*\(",
}
def extract_pd_features(code: str) -> Counter:
return Counter({k: len(re.findall(p, code)) for k, p in PD_FEATURES.items()})Let us now discuss in more detail the patterns we have seen.
# SQL Frequency Highlights
// Added window functions “highest per day” and tie-friendly ranking tasks
For example, in this Interview questionwe are asked to calculate the daily total per user, then select the highest result for each date, including ties. This is a requirement that naturally leads to window functions such as RANK() or DENSE_RANK()broken down by day.
The solution is as follows.
WITH customer_daily_totals AS (
SELECT
o.cust_id,
o.order_date,
SUM(o.total_order_cost) AS total_daily_cost
FROM orders o
WHERE o.order_date BETWEEN '2019-02-01' AND '2019-05-01'
GROUP BY o.cust_id, o.order_date
),
ranked_daily_totals AS (
SELECT
cust_id,
order_date,
total_daily_cost,
RANK() OVER (
PARTITION BY order_date
ORDER BY total_daily_cost DESC
) AS rnk
FROM customer_daily_totals
)
SELECT
c.first_name,
rdt.order_date,
rdt.total_daily_cost AS max_cost
FROM ranked_daily_totals rdt
JOIN customers c ON rdt.cust_id = c.id
WHERE rdt.rnk = 1
ORDER BY rdt.order_date;This two-step approach—first aggregate, then rank within each date—shows why window functions are ideal for “most-per-group” scenarios where relationships need to be maintained, and why basic GROUP BY logic is inadequate.
// The use of CTE increases when the query is computed.
A combination table expression (CTE) (or multiple CTEs) keeps each step readable and makes it easy to validate intermediate results.
This structure also reflects how analysts think: separating data preparation from business logic allows for query understanding, troubleshooting, and adaptation to changing needs.
// Join plus aggregation becomes the default in multi-table business metrics.
When measures live in one table and dimensions in another, you often can’t avoid JOIN clauses. After the join, GROUP BY and conditional total (SUM(CASE WHEN ... THEN ... END)) is usually the shortest path.
# Highlights of Pandas Methodology
// .merge() appears whenever the response depends on more than one table.
This Interview question A good example of a panda pattern. When calculating ridership and payment or discount logic period columns and tables, you typically combine the data first, then count or compare.
import pandas as pd
orders_payments = lyft_orders.merge(lyft_payments, on='order_id')
orders_payments = orders_payments((orders_payments('order_date').dt.to_period('M') == '2021-08') & (orders_payments('promo_code') == False))
grouped_df = orders_payments.groupby('city').size().rename('n_orders').reset_index()
result = grouped_df(grouped_df('n_orders') == grouped_df('n_orders').max())('city')Once the tables are merged, the rest of the solution reduces to a familiar one. .groupby() and the comparison phase, indicating how primitive table integration can simplify downstream logic in Pandas.
# Why do these patterns keep appearing?
// Time-based tables often call for window logic.
When a problem refers to totals “per day”, comparisons between days, or selecting the highest value for each date, usually require sorted logic. For this reason, with hierarchical functions OVER are common, especially when relationships must be preserved.
// Benefit from multi-step business rules staging
Some problems combine filtering rules, joins, and computed matrices. It is possible to write everything in one query, but it increases the difficulty of reading and debugging. CTEs help by separating enrichment from aggregation which is easier to validate, aligning with the premium vs. freemium model.
// Multi-table queries naturally increase join density.
A join is required if a metric depends on attributes stored in a different table. Once the tables are consolidated, grouped summaries are the natural next step. This aggregate form appears repeatedly in StrataScratch queries that combine event data with entity profiles.
# A practical path to faster, cleaner solutions
- If the output depends on sorted rows, expect window functions.
ROW_NUMBER()orDENSE_RANK() - If the question reads like “compute A, then compute B from A,” a WITH block usually improves clarity.
- If the dataset is split into multiple entities, plan the join early and decide on your grouping keys before writing the final selection.
- In pandas, treatment
.merge()By default when logic spans multiple data frames, then create a metric with it.groupby()and clean filtering.
# The result
The coding style follows the structure: time-based and “most per group” questions generate window functions. Multi-step business rules generate CTEs.
Multi-table matrix increases join density, and pandas mirrors the same operations .merge() And .groupby().
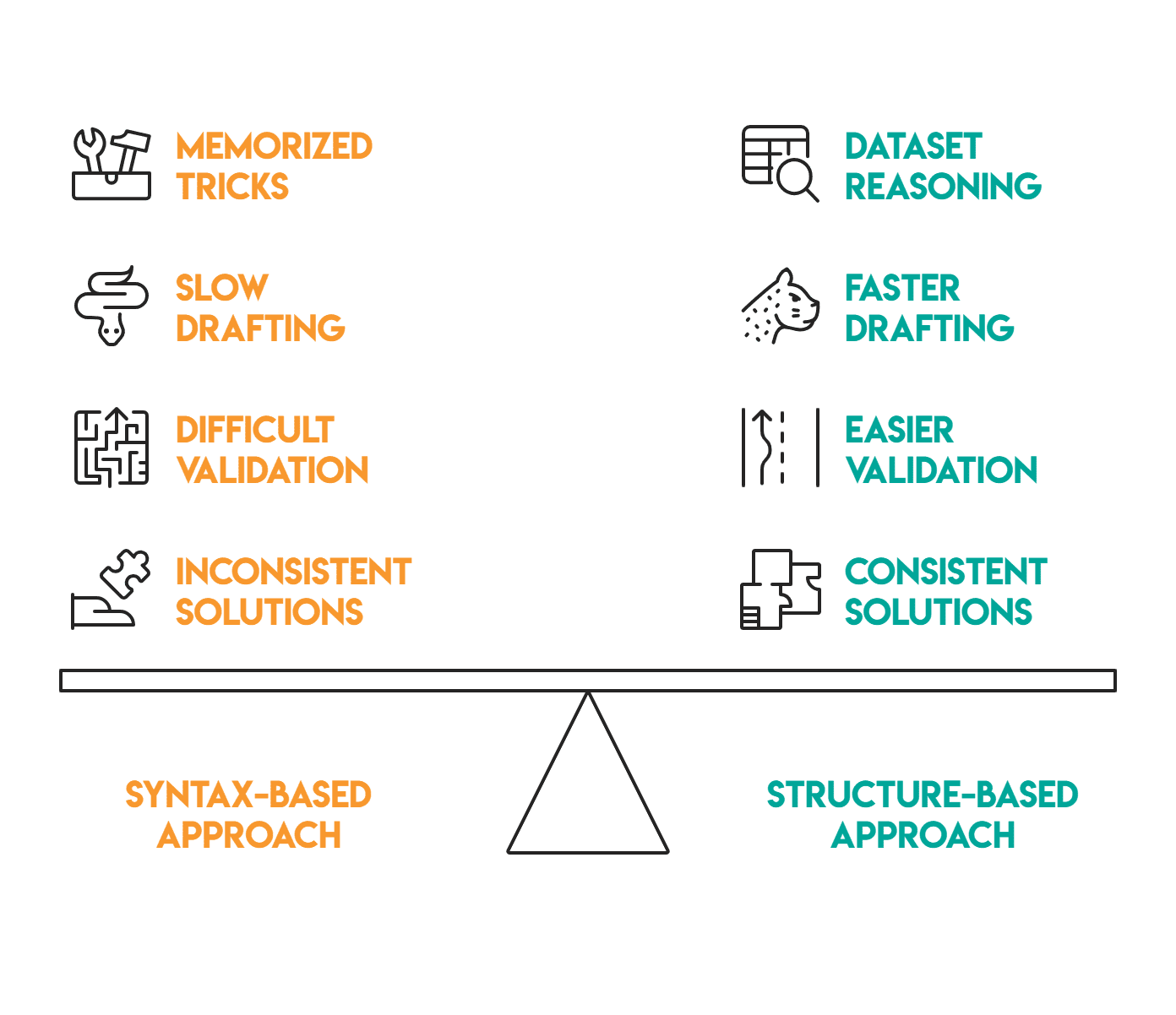
More importantly, recognizing these structural patterns early on can significantly change your approach to a new problem. Instead of starting with syntax or memorization tricks, you can reason from the dataset itself: Is it maximal per group? A step-by-step business principle? A multi-table metric?
This change in mindset allows you to anticipate the main framework before writing any code. Ultimately, this results in faster solution drafting, easier validation, and greater consistency across SQL and Pandas, because you’re answering the data structure, not just the query text.
Once you learn to recognize the shape of a dataset, you can quickly predict the dominant construct. This makes solutions faster to write, easier to debug, and more consistent across new problems.
Net Rosiedi A data scientist and product strategist. He is also an adjunct professor teaching analytics, and the founder of StrataScratch, a platform that helps data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers all things SQL.