

https://www.youtube.com/watch?v=yrln17maxs
In this project walkthrough, I will analyze the Kagal Data Science Survey to analyze the Kagal Data Science Survey for the Data Science professionals and to seek insights on the basis of years of experience. This analysis uses basic masters such as lists, loops and conditional logic. Although more advanced tools such as Pandas can smooth this process, working with the basic aggression can help you create a solid foundation for data manipulation and analysis.
Project Review
L, we assume the role of data analyst for Kegal, which examines data scientists survey data who shared details about it:
- Year of their coding experience (
experience_codingJes - Programming languages they use (
python_userFor, for, for,.r_userFor, for, for,.sql_userJes - Priority libraries and tools (
most_usedJes - Compensate (
compensationJes
Our goal is to answer two important questions.
- Which programming languages are the most common among data scientists?
- How does the compensation experience happen with years of experience?
Establish
1. Set your workplace
We will work with one .ipynb File, which can be presented in the following tools:
2. Download the Resource File
To process as well as tutorials, you will need two necessary resources: Basics.ipynb Gapter Notebook which includes all codes and analysis steps we will find together, and kaggle2021-short.csv Datastate file, which contains the Kagal survey response we will analyze.
Let’s start by loading your data from the CSV file. We will use the built -in CSV module instead of Pandas instead of Pandas:
import csv
with open('kaggle2021-short.csv') as f:
reader = csv.reader(f, delimiter=",")
kaggle_data = list(reader)
column_names = kaggle_data(0)
survey_responses = kaggle_data(1:)
print(column_names)
for row in range(0,5):
print(survey_responses(row))The output column structure and the first few rows of our data.
('experience_coding', 'python_user', 'r_user', 'sql_user', 'most_used', 'compensation')
('6.1', 'TRUE', 'FALSE', 'TRUE', 'Scikit-learn', '124267')
('12.3', 'TRUE', 'TRUE', 'TRUE', 'Scikit-learn', '236889')
('2.2', 'TRUE', 'FALSE', 'FALSE', 'None', '74321')
('2.7', 'FALSE', 'FALSE', 'TRUE', 'None', '62593')
('1.2', 'TRUE', 'FALSE', 'FALSE', 'Scikit-learn', '36288')Instructive Insight: When I first started this project, it was important to look at such raw data. He immediately. It was just showed me that all values were stored as a wire (enter the price around the number), which will not work for numerical calculations. Always take time to understand your data structure before diving into the analysis!
Cleaning data
The data needs some cleaning before we can properly analyze it. When we read the CSV file, everything comes as wire, but we need:
experience_codingAs a float (aspiring number)python_userFor, for, for,.r_userAndsql_userAs a boulin values (true/false)most_usedAs ifNoneOr a stringcompensationAs a digit
Here I transformed each column into the appropriate data type:
# Iterate over the indices so that we can update all of the data
num_rows = len(survey_responses)
for i in range(num_rows):
# experience_coding
survey_responses(i)(0) = float(survey_responses(i)(0))
# python_user
if survey_responses(i)(1) == "TRUE":
survey_responses(i)(1) = True
else:
survey_responses(i)(1) = False
# r_user
if survey_responses(i)(2) == "TRUE":
survey_responses(i)(2) = True
else:
survey_responses(i)(2) = False
# sql_user
if survey_responses(i)(3) == "TRUE":
survey_responses(i)(3) = True
else:
survey_responses(i)(3) = False
# most_used
if survey_responses(i)(4) == "None":
survey_responses(i)(4) = None
else:
survey_responses(i)(4) = survey_responses(i)(4)
# compensation
survey_responses(i)(5) = int(survey_responses(i)(5))Let’s confirm that our data change worked correctly:
print(column_names)
for row in range(0,4):
print(survey_responses(row))Output:
('experience_coding', 'python_user', 'r_user', 'sql_user', 'most_used', 'compensation')
(6.1, True, False, True, 'Scikit-learn', 124267)
(12.3, True, True, True, 'Scikit-learn', 236889)
(2.2, True, False, False, None, 74321)
(2.7, False, False, True, None, 62593)
Instructive Insight: I spent hours debugging why the calculations were not working, just to realize that I was trying to take math action on the wires instead of numbers! Now, checking the types of data in any analysis is one of my first steps.
To analyze the use of programming language
Now that our data has been cleared, let’s find out how many data scientists use in each programming language:
# Initialize counters
python_user_count = 0
r_user_count = 0
sql_user_count = 0
for i in range(num_rows):
# Detect if python_user column is True
if survey_responses(i)(1):
python_user_count = python_user_count + 1
# Detect if r_user column is True
if survey_responses(i)(2):
r_user_count = r_user_count + 1
# Detect if sql_user column is True
if survey_responses(i)(3):
sql_user_count = sql_user_count + 1To show the results in a more readable form of reading, I would use a dictionary and formed indoor:
user_counts = {
"Python": python_user_count,
"R": r_user_count,
"SQL": sql_user_count
}
for language, count in user_counts.items():
print(f"Number of {language} users: {count}")
print(f"Proportion of {language} users: {count / num_rows}\n")Output:
Number of Python users: 21860
Proportion of Python users: 0.8416432449081739
Number of R users: 5335
Proportion of R users: 0.20540561352173412
Number of SQL users: 10757
Proportion of SQL users: 0.4141608593539445Instructive Insight: I like to use F -strings (formated indoor) to display results. Before I discover them, I will use the string connection with it + Signs and numbers had to turn into a wire by using str(). F -strings enable everything to read clean and more. Just add one f Before the string and use curly curiosity {} To add variables!
The results clearly show that the data science field dominates, in which more than 84 % of respondents use. SQL is the second most popular in about 41 %, while about 20 % of R used to use.
Experience and compensation analysis
Now, seek the second question: How does the compensation experience happen with years of experience? First, I will separate these columns in their own lists to make it easier to work with them:
# Aggregating all years of experience and compensation together into a single list
experience_coding_column = ()
compensation_column = ()
for i in range(num_rows):
experience_coding_column.append(survey_responses(i)(0))
compensation_column.append(survey_responses(i)(5))
# testing that the loop acted as-expected
print(experience_coding_column(0:5))
print(compensation_column(0:5))
Output:
(6.1, 12.3, 2.2, 2.7, 1.2)
(124267, 236889, 74321, 62593, 36288)Let’s see some summary figures for years of experience:
# Summarizing the experience_coding column
min_experience_coding = min(experience_coding_column)
max_experience_coding = max(experience_coding_column)
avg_experience_coding = sum(experience_coding_column) / num_rows
print(f"Minimum years of experience: {min_experience_coding}")
print(f"Maximum years of experience: {max_experience_coding}")
print(f"Average years of experience: {avg_experience_coding}")Output:
Minimum years of experience: 0.0
Maximum years of experience: 30.0
Average years of experience: 5.297231740653729Although these summary stats are helpful, a concept will give us a better understanding of division. Let’s create a hustagram of years of experience:
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(experience_coding_column)
plt.show()
Hastogram shows that most of the data scientists have a relatively FEW experience (0-5 years), more experience with professional people’s long tail.
Now, see compensation data:
# Summarizing the compensation column
min_compensation = min(compensation_column)
max_compensation = max(compensation_column)
avg_compensation = sum(compensation_column) / num_rows
print(f"Minimum compensation: {min_compensation}")
print(f"Maximum compensation: {max_compensation}")
print(f"Average compensation: {round(avg_compensation, 2)}")Output:
Minimum compensation: 0
Maximum compensation: 1492951
Average compensation: 53252.82Instructive Insight: I was surprised when I first saw a maximum compensation of about $ 1.5 million! This is probably an outlet and may be that our average will be sketch. In a more thorough analysis, I will investigate it further and probably remove the extremes of the most outgoing. Always ask data points that are unusually high or less known.
Let’s make a hustagram for compensation too:
plt.hist(compensation_column)
plt.show()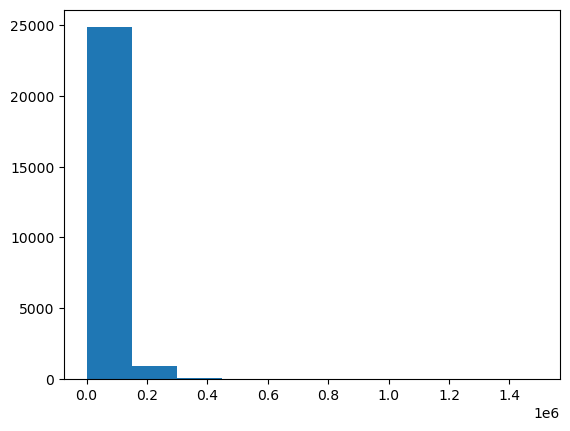
The histogram for compensation is the far -right Scachel, most of which are clusted on the left and some high values are spread to the right. This makes it difficult to see the details of the distribution.
To analyze compensation through the experience level
To better understand the relationship between experience and compensation, let’s classify the experience in boxes and analyze the average compensation of each bin.
First, let’s add a new category column to your datastas that groups years experience:
for i in range(num_rows):
if survey_responses(i)(0) < 5:
survey_responses(i).append("<5 Years")
elif survey_responses(i)(0) >= 5 and survey_responses(i)(0) < 10:
survey_responses(i).append("5-10 Years")
elif survey_responses(i)(0) >= 10 and survey_responses(i)(0) < 15:
survey_responses(i).append("10-15 Years")
elif survey_responses(i)(0) >= 15 and survey_responses(i)(0) < 20:
survey_responses(i).append("15-20 Years")
elif survey_responses(i)(0) >= 20 and survey_responses(i)(0) < 25:
survey_responses(i).append("20-25 Years")
else:
survey_responses(i).append("25+ Years")Now, let’s make separate lists for compensation in each experience.
bin_0_to_5 = ()
bin_5_to_10 = ()
bin_10_to_15 = ()
bin_15_to_20 = ()
bin_20_to_25 = ()
bin_25_to_30 = ()
for i in range(num_rows):
if survey_responses(i)(6) == "<5 Years":
bin_0_to_5.append(survey_responses(i)(5))
elif survey_responses(i)(6) == "5-10 Years":
bin_5_to_10.append(survey_responses(i)(5))
elif survey_responses(i)(6) == "10-15 Years":
bin_10_to_15.append(survey_responses(i)(5))
elif survey_responses(i)(6) == "15-20 Years":
bin_15_to_20.append(survey_responses(i)(5))
elif survey_responses(i)(6) == "20-25 Years":
bin_20_to_25.append(survey_responses(i)(5))
else:
bin_25_to_30.append(survey_responses(i)(5))Let’s see how many people come in every experience:
# Checking the distribution of experience in the dataset
print("People with < 5 years of experience: " + str(len(bin_0_to_5)))
print("People with 5 - 10 years of experience: " + str(len(bin_5_to_10)))
print("People with 10 - 15 years of experience: " + str(len(bin_10_to_15)))
print("People with 15 - 20 years of experience: " + str(len(bin_15_to_20)))
print("People with 20 - 25 years of experience: " + str(len(bin_20_to_25)))
print("People with 25+ years of experience: " + str(len(bin_25_to_30)))Output:
People with < 5 years of experience: 18753
People with 5 - 10 years of experience: 3167
People with 10 - 15 years of experience: 1118
People with 15 - 20 years of experience: 1069
People with 20 - 25 years of experience: 925
People with 25+ years of experience: 941Let’s imagine this division:
bar_labels = ("<5", "5-10", "10-15", "15-20", "20-25", "25+")
experience_counts = (len(bin_0_to_5),
len(bin_5_to_10),
len(bin_10_to_15),
len(bin_15_to_20),
len(bin_20_to_25),
len(bin_25_to_30))
plt.bar(bar_labels, experience_counts)
plt.title("Years of Experience")
plt.xlabel("Years")
plt.ylabel("Count")
plt.show()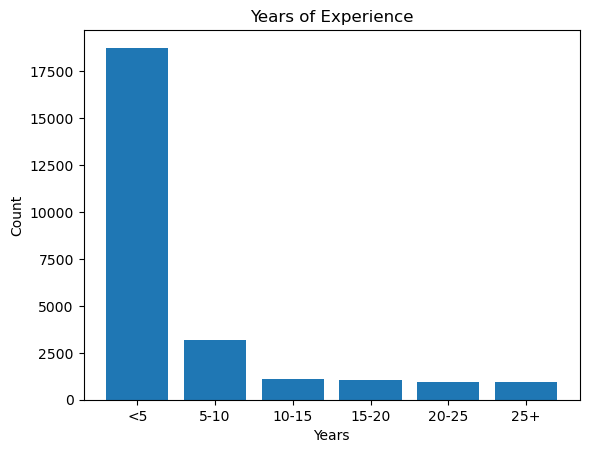
Instructive Insight: This concept clearly shows that the majority of respondents (over 18,000) have less than 5 years of experience. Many newcomers have entered this profession in recent years, how fast the data science field has increased.
Now, let’s calculate and display the average compensation of each experience of each experience:
avg_0_5 = sum(bin_0_to_5) / len(bin_0_to_5)
avg_5_10 = sum(bin_5_to_10) / len(bin_5_to_10)
avg_10_15 = sum(bin_10_to_15) / len(bin_10_to_15)
avg_15_20 = sum(bin_15_to_20) / len(bin_15_to_20)
avg_20_25 = sum(bin_20_to_25) / len(bin_20_to_25)
avg_25_30 = sum(bin_25_to_30) / len(bin_25_to_30)
salary_averages = (avg_0_5,
avg_5_10,
avg_10_15,
avg_15_20,
avg_20_25,
avg_25_30)
# Checking the distribution of experience in the dataset
print(f"Average salary of people with < 5 years of experience: {avg_0_5}")
print(f"Average salary of people with 5 - 10 years of experience: {avg_5_10}")
print(f"Average salary of people with 10 - 15 years of experience: {avg_10_15}")
print(f"Average salary of people with 15 - 20 years of experience: {avg_15_20}")
print(f"Average salary of people with 20 - 25 years of experience: {avg_20_25}")
print(f"Average salary of people with 25+ years of experience: {avg_25_30}")Output:
Average salary of people with < 5 years of experience: 45047.87484669119
Average salary of people with 5 - 10 years of experience: 59312.82033470161
Average salary of people with 10 - 15 years of experience: 80226.75581395348
Average salary of people with 15 - 20 years of experience: 75101.82694106642
Average salary of people with 20 - 25 years of experience: 103159.80432432433
Average salary of people with 25+ years of experience: 90444.98512221042Finally, let’s imagine this relationship:
plt.bar(bar_labels, salary_averages)
plt.title("Average Salary by Years of Experience")
plt.xlabel("Years")
plt.ylabel("Salary Average")
plt.axhline(avg_compensation, linestyle="--", color="black", label="overall avg")
plt.show()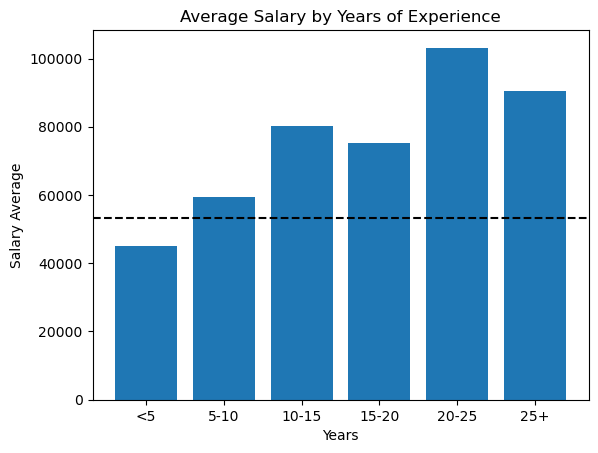
Instructive Insight: I was surprised to find that the relationship between experience and salary is not at all linear. Although salaries usually increase with experience, the 15-20 year limit is unexpected. I suspect this may be due to other factors such as industry, character type, or other compensation location. This is a reminder that the connection does not always follow the sample we expect!
The horizontal dashed line represents the overall average compensation in all levels of experience. Note that this is only higher than the lowest experience bracket, which makes it understood that the majority of respondents have less than 5 years experience, which reduces the overall average.
Key results
From this analysis, we can draw several interesting conclusions:
- Popularity of programming language:
- Azigar is the most famous language ever, which uses 84 % of data scientists
- SQL is second with 41 % use
- R is less common but is still important in 20 % use
- Experienced partition:
- The majority of data scientists (72 %) have less than 5 years experience
- This shows that data science is a relatively Young field with many newcomers
- Compensation Trends:
- Compensation is usually the above trend as the experience increases
- The highest average compensation is for those who have a 20-25 year experience (3 103,000)
- With some fluctuations in the trend, the relationship is not linear at all
Next steps and further analysis
This analysis provides valuable insights, but there are many ways we can increase.
- Investigrate out of compensation:
- The maximum compensation of about $ 1.5 million seems abnormally high and may be our average
- Data cleaning can give more accurate results to remove delete or cap -out layers
- Deep language analysis:
- Are some programming languages associated with higher salaries?
- Are people who know multiple languages (such as, Azigar and SQL)?
- Library and device analysis:
- We have not yet discovered that
most_usedColumn - Do some libraries use different salaries (such as tensilers vs. skaten)?
- We have not yet discovered that
- Time -based analysis:
- This dataset is from 2021 – comparing this with a recent survey can show changing trends
If you are new, start with our basic things for the path of data analysis skills to create the basic skills needed for this project.
Looking more about Kagal? Check these posts:
The final views
I hope this walkthrough has been helpful in showing how to analyze data using basic basic skills. Even without modern tools such as pandas, we can remove meaningful insights from data using basic programming techniques.
If you have questions about this analysis or you want to share your insights, he should be joked in this debate Data Quest Community. I would like to hear how you will approach this datastate!