

Much of the advice on generative engine optimization best practices starts from the same place: find the indicators people use with AI tools, track which ones give your brand visibility, and create content around the highest-volume queries.
The problem? This figure is largely an estimate.

Generative Engine Optimization (GEO) is still so new that the infrastructure to measure it accurately does not yet exist. Think about how GEO is different from SEO: the mature, reliable signals you expect from tools like Seemrush or Ahrefs took years to develop. GEO measurement does not exist yet. What the platform calls “prompt volume” is modeled, estimated, and often directionally inaccurate.
This post explains why instant volume is an unreliable foundation for your GEO strategy and what top-performing teams do instead.
Key takeaways
- “Prompt volume” is a modeled estimate, not actual user data, making it an unreliable starting point for GEO decisions.
- AI behavior is inconsistent; People’s phrases signal differently and models give different answers, making it difficult to trust small-scale patterns.
- AI “rankings” are unstable; Studies show that results are constantly changing, so tracking position doesn’t translate to the way you track SEO.
- Most data sources, whether panels or APIs, are biased or do not reflect actual user behavior in AI tools.
- Referral flows are high, meaning sources and visibility change from month to month even for the same indicator.
- GEO tools are still preliminary and directional, not definitive; Treat them accordingly.
- Clustering prompts around the native language of your ICP performs better than chasing vendor curated query lists.
- A consistent monitoring schedule is more important than obsessing over a single data point.
Why Instant Volume Misleads Your GEO Strategy
1. LLMs do not have search volume: it is estimated, not measured
The most basic problem is that there is no true “AI search volume” in the way Google displays search query data. LLMs do not publish query frequency or search volume equivalents. Their answers vary, sometimes subtly and sometimes dramatically, even to the same questions, due to possible decoding and immediate context. They also rely on hidden context properties such as user history, session state, and embeddedness that are opaque to external observers. What platforms sell as “prompt volume” is a modeled estimate, not a direct measurement.
2. LLM answers are non-negotiable in nature.
Traditional keyword volume works because millions of people type the same phrase into Google and those queries are logged. AI interactions are fundamentally different. Search behavior in traditional SEO is repetitive, with millions of similar phrases driving static volume metrics. LLM interactions are conversational and variable. People rephrase questions differently, often in the same session, making pattern recognition difficult with small data sets.
This instability is baked into how LLMs work. They produce text using probabilistic methods, choosing words based on their probabilities rather than following a set pattern. The same prompt can elicit different responses, making it difficult to draw consistent and accurate conclusions.
3. SparkToro’s research shows that ratings are essentially random.
The most compelling evidence comes from a historical study by Rand Fishkin and Gumshoe.ai in January 2026. They tested 2,961 prompts among 600 volunteers on ChatGPT, Claude, and Google AI. Finding: There is less than a one in 100 chance that any two answers will list the same brand, and less than one in 1,000 chance of the same list in the same order. As Fishkin bluntly concludes, any tool that assigns a “hierarchical position in AI” is essentially creating one.
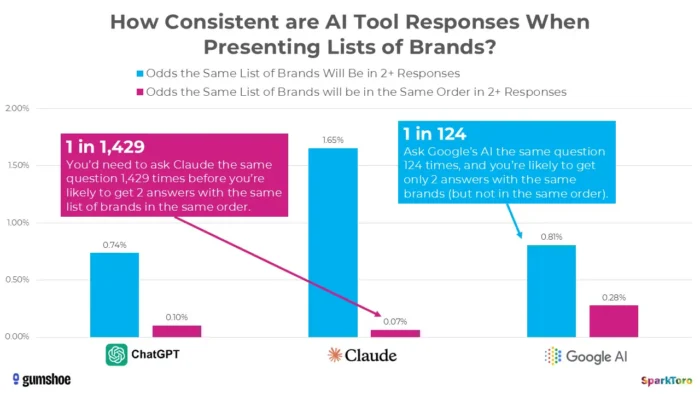
SparkToro’s research highlights significant variation in AI-generated brand recommendations even when the same indicators are used, suggesting that point-in-time AI visibility metrics may reflect fluctuating rather than sustainable performance indicators.
4. Panel-based methodology has inherent bias problems.
Platforms like Deep rely on opt-in consumer panels to source their instant data. Deep license conversations from multiple, double-opt-in consumer panels of True Response Engine users, with millions of prompts per month, and apply advanced probabilistic modeling to drive frequency, intent, and sentiment across broader populations.
While this sounds robust, the opt-in nature of these panels means that the sample may be skewed towards more tech-savvy, engaged users, rather than a representative cross-section of how the general population actually approaches AI tools.
5. API queries do not reflect real human behavior.
Many tools query AI models through an API to mimic user gestures, but this creates another gap. Most AI tracking tools rely on API calls rather than simulating human interface usage, and preliminary research suggests that API results may differ from interface results, although the magnitude and implications of these differences require further investigation. The API-centric nature of the query data also means that the results don’t match what humans actually search for.
6. The flow of referrals is huge and unpredictable.
Even if you ignore everything above, the monthly stability of AI references is surprisingly low. One study intensively measured referrals over an extended month and observed large changes in referral domains for the same indication as well. Google AI Review and ChatGPT showed monthly variations of dozens of percentage points.
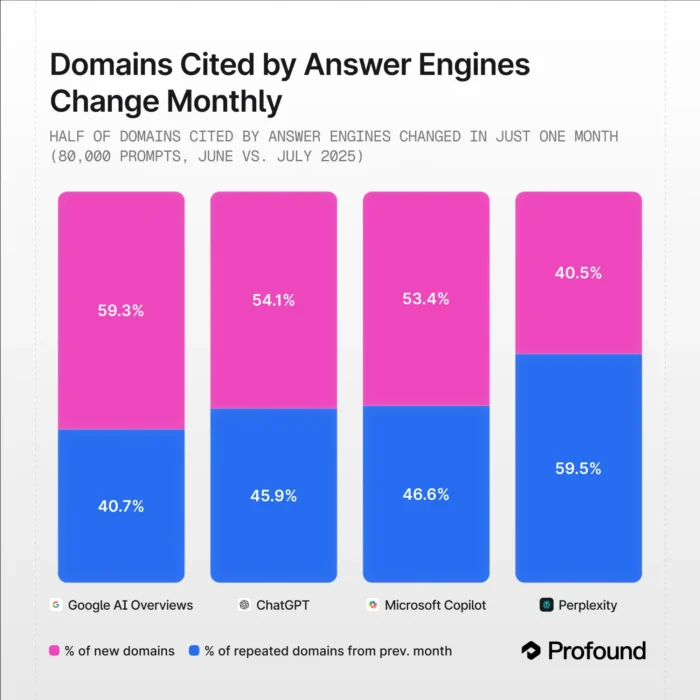
This means the “volume” associated with any prompt today may look completely different next month, making it an unreliable basis for content investment decisions.
7. We’re in the pre-Simmerish era: Tools don’t have the infrastructure yet
We are still in the pre-semrush/moz/letter era for LLM. No one has complete visibility of the LLM impact on their business today. Be wary of any vendor or consultant promising full visibility, as this is not yet possible. Current tracking data should be considered indicative and useful for decisions, but not definitive.
Generative Engine Optimization Best Practices: What to Do Instead
Prompt volume is one signal among many, and right now it’s one of the weakest. Here are generative engine optimization best practices that actually hold up.
Start with your ICP, not the dashboard.
Instead of making a quick volume estimate of your GEO content preferences, start with what you know about your audience. The strongest signal you have is your ideal customer profile. What problems are your best customers hiring you to solve? What language do they use to describe these problems? Those pain points, not quick estimates from a vendor model, should be the basis of what you improve in AI responses.
Source: Smarketers
If you’ve done solid ICP work, you’re already sitting on better data than any instant volume tool can give you.
Go where your audience is already talking.
Layer in real audience research by going where your audience speaks openly and honestly. Reddit threads, niche forums, LinkedIn comments, Slack communities, and review sites like G2 and Trustpilot are places where people ask unfiltered questions in their own words. This is exactly the kind of natural language that closely maps to how one would prompt an AI tool. If your ICP is repeatedly asking “How do I justify the ROI of X to my CFO”, that short piece of content is far more reliable than the instant volume number associated with a vendor’s curated query.
Review your own customer interactions.
Customer-facing teams are one of the most underutilized sources of GEO intelligence. Sales call recordings, support tickets, customer interviews, and onboarding conversations are used by real buyers when they’re stuck, skeptical, or evaluating options. This language carries over into your content and ultimately the AI responses. If your sales team hears the same objection every week, there’s a good chance someone is asking AI the same question.
Cluster and organize prompts around your audience’s language.
Once you have raw input from your ICP work, forums, and customer interactions, the next step is to structure it. Instead of treating each possible indicator as an isolated target, group them by intent and theme.
Quick clustering around similar topics or pain points helps you see patterns in how your audience thinks about a problem, not just how they phrase a question. A cluster around “how to measure GEO success” might include tips on metrics, reporting, stakeholder communication, and benchmarking. Each of these deserves content, and the overlap between them tells you what your core narrative should be.
This is a significant change from the logic of keyword research. When you’re thinking about GEO vs. AEO, the organizing principle remains the same: local authority on the problems your audience is trying to solve. Quick organization by intent and theme is what allows you to systematically build that authority.
Use prompt volume tools for what they’re actually good at.
None of this means completely abandoning platforms like Deep or RightSonic. Used correctly, they’re useful for truly directional awareness: finding topic gaps, monitoring whether your brand is appearing in the right conversations, and tracking share of voice against competitors over time.
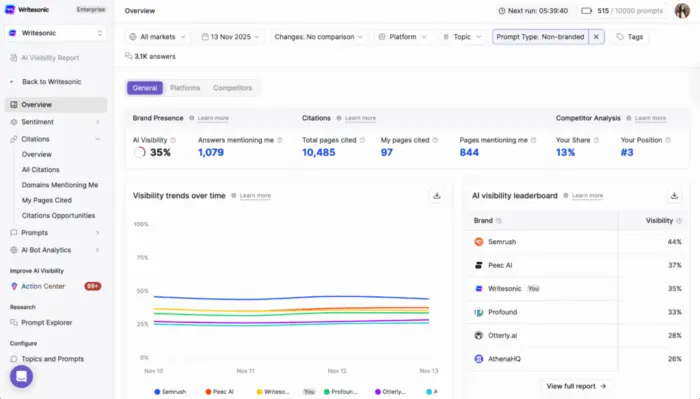
The mistake is using them as a substitute for keyword volume and letting their guesses drive your creation. Let your ICP, audience research, and real customer conversations tell you what to optimize for. Then use the instant volume data to pressure test and monitor, not make decisions.
Create a monitoring schedule that actually works.
Given how much citation flow exists in AI outputs, monitoring needs to be structured and consistent rather than reactive. Checking your brand’s AI visibility once a quarter isn’t enough. A monthly monitoring schedule for your primary prompt clusters gives you a good baseline to see meaningful shifts without over-indexing on the noise.
Here’s how to approach it in practice. Create a defined list of 20 to 30 prompts that reflect your most common ICP questions. Run them at a set cadence, at least monthly, on the platforms your audience uses the most, such as ChatGPT, Perplexity, and Google AI Overviews. Track whether your brand, your content, or your competitors are appearing. Note the changes, but don’t overreact to one-month swings, given how much variation there is. What you’re looking at are three to six month directional trends, not week-to-week positions.
This is what separates teams with a true AI search optimization strategy from those reacting to dashboard alerts. Notification of surveillance; It does not decide.
The bottom line
Prompt volume tries to almost demand what you may already have direct access to. Brands that win in AI search aren’t the ones chasing the most tracked indicators. They are the ones who understand their audience so deeply that they can reveal in the answers what their customers are actually looking for.

See how my agency can operate. More Traffic to your website
- SEO – Unlock more SEO traffic. See real results.
- Content Marketing – Our team creates epic content that will get shared, get links, and attract traffic.
- Paid media – Effective paid strategy with clear ROI.
Book a call
Unlock thousands. Keywords with Ubersuggest
Ready to outdo your competitors?
- Find long-tail keywords with high ROI.
- Search 1000’s of keywords instantly.
- Turn searches into visits and conversions.
Free keyword research tool