

Photo by editor
# Introduction
to get Labeled data —that is, the ground-truth target labeled data—is a fundamental measure for most supervised machine learning models such as random forests, logistic regression, or neural network-based classifiers. While a major difficulty in many real-world applications lies in obtaining a sufficient amount of labeled data, there are times when, even after checking this box, there may still be another significant challenge: class imbalance.
Class imbalance Occurs when a labeled dataset contains classes with a very different number of observations, usually with one or more classes overrepresented. This issue often causes problems when building machine learning models. Put another way, training a predictive model like a classifier on balanced data leads to issues like biased decision limits, poor recall on minority classes, and misleadingly low precision, which in practice means that the model performs well “on paper” but once determined, we fail in the most important cases. To be legitimate.
Artificial Minority Oversampling Technique (SMOTE) A data-driven resampling technique is a data-driven resampling technique to deal with this problem by generating new samples belonging to the minority class, such as fake transactions, through an interference technique between existing real examples.
This article briefly introduces smoot and then explains the lens, how to use it correctly, why it is often misused, and how to avoid these situations.
# What is smoke and how does it work?
Smote is a data augmentation technique for dealing with class imbalance problems in machine learning, especially in supervised models such as classification. In classification, when at least one class is significantly underrepresented compared to others, the model can easily be biased towards the majority class, leading to poor performance, especially when it comes to predicting rare classes.
To meet this challenge, Smoot creates artificial data examples for the minority class, not by replicating existing events, but by interpolating between the minority class and a sample of its nearest neighbors in the space of available features: this process is, in essence, “filling in” regions of such regions that contain existing minorities, which increase the surrounding minorities.
Smoky iterates over each minority instance, identifies its \(k\) nearest neighbors, and then generates a new synthetic point along the “line” between the sample and a randomly chosen neighbor. Applying these simple steps iteratively results in a new set of minority class examples, so that the model can be trained based on the rich representation of the minority class (ES) in the dataset, resulting in a more efficient, less biased model.
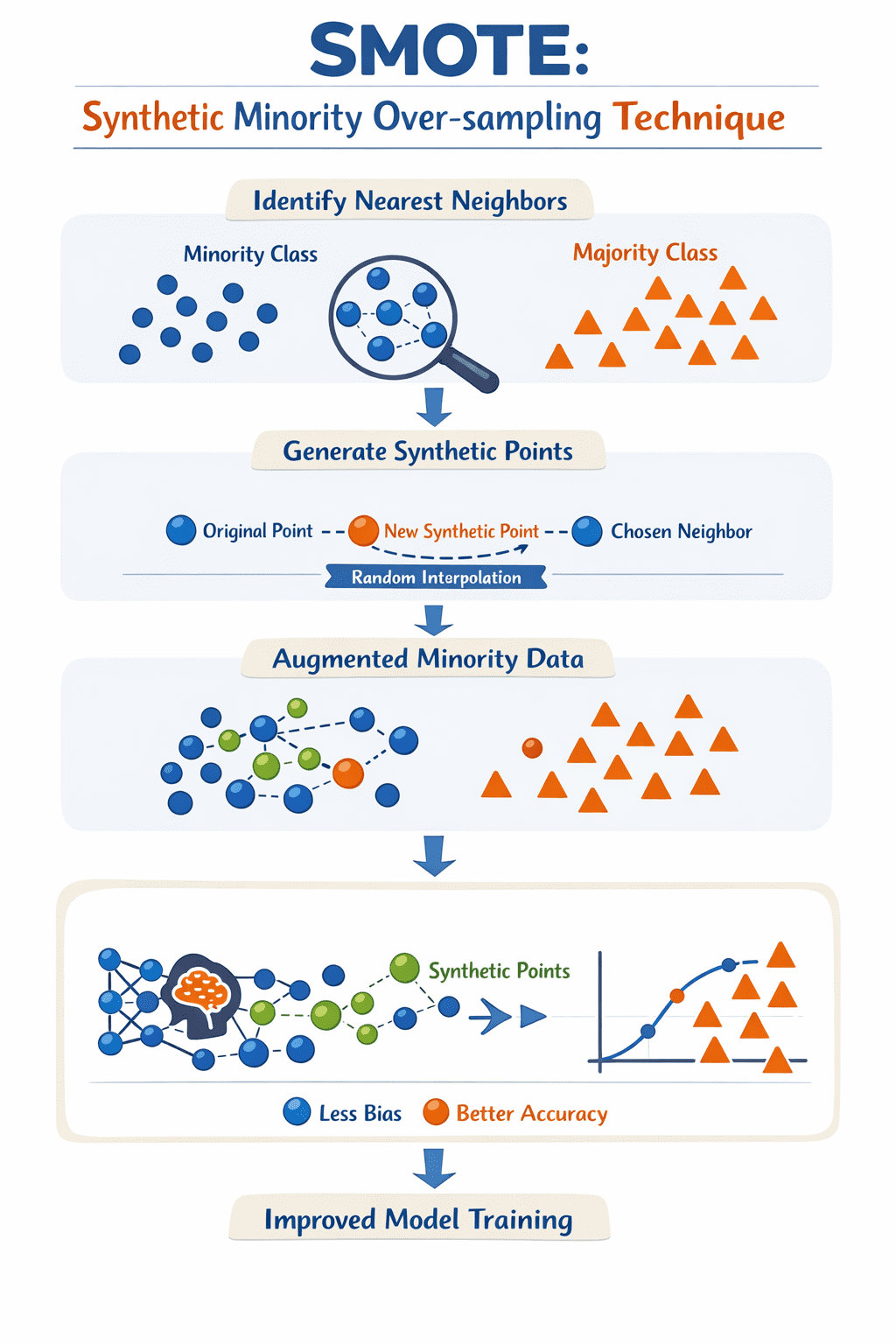
How does smoky work? Photo by author
# Implementing smoot correctly in Python
To avoid the data leakage problems mentioned earlier, it is better to use a pipeline. Disequilibrium learning The library provides a pipeline object that ensures that only the training data is applied during each part of cross-validation or a simple holdout split, leaving the test set untouched and representative of real-world data.
The following example shows how to merge smote into one Machine learning Using a workflow scikit-learn And imblearn:
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# Split data into training and testing sets first
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Define the pipeline: Resampling then modeling
# The imblearn Pipeline only applies SMOTE to the training data
pipeline = Pipeline((
('smote', SMOTE(random_state=42)),
('classifier', RandomForestClassifier(random_state=42))
))
# Fit the pipeline on training data
pipeline.fit(X_train, y_train)
# Evaluate on the untouched test data
y_pred = pipeline.predict(X_test)
print(classification_report(y_test, y_pred))By using Pipelineyou ensure that change only occurs in the context of training. This prevents artificial information from “bleeding” into your evaluation set, and provides a more honest assessment of how your model will handle balanced classes in preparation.
# Common misuses of smoke
Let’s look at three common ways it is misused Machine learning Workflow, and how to avoid these misuses:
- Before dividing the dataset into training and test sets, applying the smoke: This is a very common mistake that inexperienced data scientists can make frequently (and in most cases accidentally). Creates new synthetic examples based on smoke All available dataand injecting artificial points that will later be both training and test partitions is a “not perfect” recipe for artificially expanding the model’s evaluation matrix unrealistically. The correct approach is simple: first partition the data, then just smooth on the training set. Also thinking about applying K-fold cross-validation? Even better
- More balance: Another common mistake is to close your eyes until there is an exact match between class proportions. In many cases, achieving this perfect balance is not only unnecessary but may also be inconsistent and unrealistic given the domain or class structure. This is especially true in multiclass datasets with many sparse minority classes, where smoky can produce artificial examples that cross boundaries or lie in regions where no real data examples can be found: in other words, noise can be inadvertently introduced, such as over-fitting results from the model. The general approach is to work slowly and try to train your model with subtle, incremental additions to minority class proportions.
- Ignoring the context surrounding the matrix and model: A model’s overall accuracy metric is a convenient and interpretive metric to obtain, but it can also be a misleading and “hollow metric” that does not reflect your model’s failure to detect minority class cases. This is a critical issue in high-stakes domains such as banking and healthcare, with scenarios such as rare disease detection. Meanwhile, smoothing can help improve reliability on metrics like recall, but it can be less relevant to its counterpart, precision, by introducing artificial noise patterns that can misalign with business goals. To evaluate not only your model properly, but also the effectiveness of smoke in its performance, jointly focus on metrics such as recall, F1-score, Matthews correlation coefficient (MCC, a “summary” of a complete confusion matrix), or precision-recall area under the curve (PR-AUC). Similarly, consider alternative strategies such as class weighting or threshold tuning as part of Smote’s application to further increase effectiveness.
# Concluding Remarks
This article revolves around smog: a commonly used technique to remove class imbalance in the construction of some machine learning classifiers based on real-world datasets. We’ve identified some common misuses of this technique and practical advice to try to avoid them.
Ivan Palomares Carrascosa Is a leader, author, speaker, and consultant in AI, Machine Learning, Deep Learning, and LLMS. He trains and guides others in real-world applications of AI.