

Photo by author
# Introduction
Remember when building a full-stack application required expensive cloud credits, expensive API keys, and a team of engineers? Those days are officially over. By 2026, developers can build, deploy and scale production-ready applications using nothing but free tools, including Major language models (LLMs) that powers his intelligence.
The landscape has changed dramatically. Open source models now challenge their commercial counterparts. Free AI coding assistants have grown from simple automation tools to full-fledged coding agents that can build entire features. And perhaps most importantly, you can drive the latest models locally or through generous free tiers without spending a dime.
In this comprehensive article, we’ll build a real-world application—an AI meeting notes summarizer. Users will upload voice recordings, and our app will transcribe them, extract key points and action items, and display everything in a clean dashboard, all using completely free tools.
Whether you’re a student, a bootcamp graduate, or an experienced developer looking to prototype an idea, this tutorial will show you how to take advantage of the best free AI tools available. Start by understanding why free LLMs are doing so well today.
# Understanding why free large language models work now
Just two years ago, building an AI-powered app meant budgeting for OpenAI API credits or renting expensive GPU instances. Economics has fundamentally changed.
The distinction between commercial and open source LLMs has almost disappeared. Love the models. GLM-4.7-Flash Zhipu demonstrates with AI that open source can achieve state-of-the-art performance while remaining completely free to use. likewise, LFM2-2.6B-transcript Designed specifically for meeting summaries and runs fully on-device with cloud-level quality.
What this means for you is that you are no longer locked into a single vendor. If one model doesn’t work for your use case, you can switch to another without changing your infrastructure.
// Join the self-hosted movement
There is a growing preference for models that run native AI on your own hardware rather than sending data to the cloud. It’s not just about cost; It’s about privacy, latency and control. As with equipment Allama And LM Studioyou can run powerful models on laptops.
// Adopting a “bring your own key” model
A new category of tools has emerged: open-source applications that are free but require you to provide your API keys. This gives you ultimate flexibility. You can use Google. Gemini API (which offers hundreds of free applications per day) or run fully native models with zero ongoing costs.
# Choosing Your Free Artificial Intelligence Stack
Our breakdown of the best free options for each application component includes a selection of tools that balance performance with ease of use.
// Layers of Transcription: Speech to Text
To convert audio to text, we have the best free speech-to-text (STT) tools.
| Tool | Kind of | Free tier | Best for |
|---|---|---|---|
| Open AI Whisper | Open source model | Unlimited (self-hosted) | Accuracy, multiple languages. |
| Whisper.cpp | Privacy-focused implementation | Unlimited (Open Source) | Privacy sensitive scenarios. |
| Gemini API | Cloud API | 60 requests/min | Rapid prototyping |
For our project, we will use The whisperwhich you can run locally or through free hosting options. It supports more than 100 languages and produces high-quality transcripts.
// Summary and Analysis: The Big Language Model
This is where you have the most choices. All options below are completely free:
| Model | The provider | Kind of | specialization |
|---|---|---|---|
| GLM-4.7-Flash | Zhipu AI | Cloud (Free API) | General Purpose, Coding |
| LFM2-2.6B-transcript | Liquid AI | local/on device | Summary of the meeting |
| Gemini 1.5 Flash | Cloud API | Long context, free tier | |
| Swallow GPT-OSS. | Tokyo Tech | Local/Self-hosted | Japanese/English reasoning |
For our meeting summary, LFM2-2.6B-transcript The model is particularly interesting; It was literally trained for this exact use case and runs in less than 3GB of RAM.
// Accelerated Development: Artificial Intelligence Coding Assistant
Before we write a single line of code, consider these tools that help us build more efficiently within an integrated development environment (IDE):
| Tool | Free tier | Kind of | Key feature |
|---|---|---|---|
| partner | Totally free | VS Code Extensions | SPEC-powered, multi-agent |
| Codem | Unlimited free | IDE extension | 70+ languages, fast estimation |
| Cline | Free (BYOK) | VS Code Extensions | Independent file editing |
| Continue | Fully open source | IDE extension | Works with any LLM. |
| bolt.diy | Self-hosted | Browser IDE | Full stack generation |
Our recommendation: For this project, we’ll use Codeium for its unlimited free tier and speed, and we’ll keep Continue as a backup when we need to switch between different LLM providers.
// Reviewing Traditional FreeStack
- Front End: Reaction (Free and Open Source)
- Background: Fast API (Python, free)
- Database: SQLite (file based, no server required)
- Deployment: Versailles (Generous free tier) + Render (for backend)
# Project Plan Review
Description of Application Workflow:
- User uploads an audio file (meeting recording, voice memo, lecture)
- The backend receives the file and sends it to Whisper for transcription.
- Transcripts are sent to LLM for abstracting.
- The LLM draws out key discussion points, action items and decisions.
- The results are stored in SQLite.
- The user sees a clean dashboard with transcript, summary and action items.
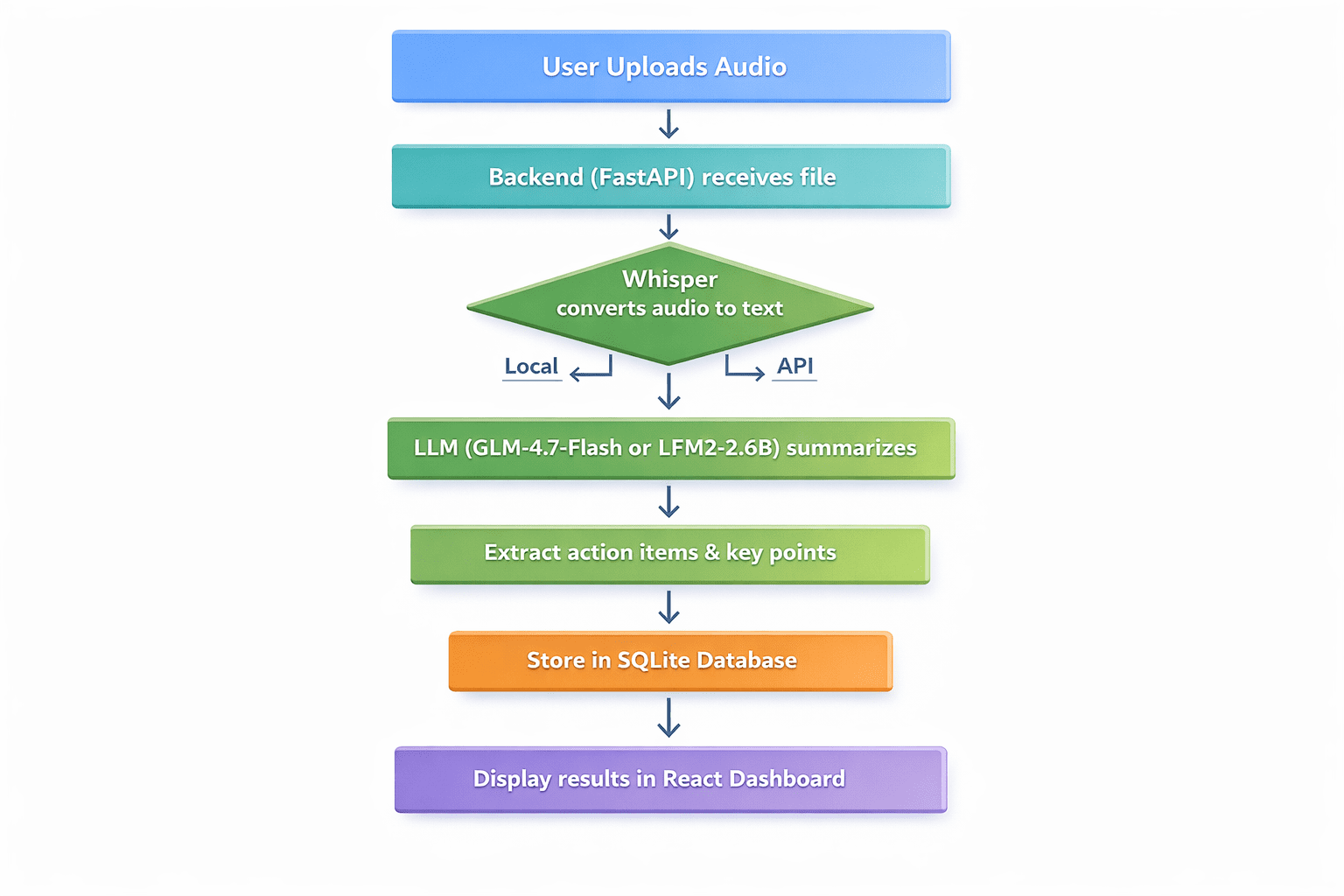
Professional Flow Chart Diagram with Seven Sequential Steps | Photo by author
// Conditions
- Python 3.9+ is installed.
- Node.js and npm are installed.
- Basic familiarity with Python and React
- A code editor (VS Code recommended)
// Step 1: Setting up the backend with Fast API
First, create our project directory and set up a virtual environment:
mkdir meeting-summarizer
cd meeting-summarizer
python -m venv venvActivate the virtual environment:
# On Windows
venv\Scripts\activate
# On Linux/macOS
source venv/bin/activateInstall required packages:
pip install fastapi uvicorn python-multipart openai-whisper transformers torch openaiNow, make it main.py File for our FastAPI application and add this code:
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.middleware.cors import CORSMiddleware
import whisper
import sqlite3
import json
import os
from datetime import datetime
app = FastAPI()
# Enable CORS for React frontend
app.add_middleware(
CORSMiddleware,
allow_origins=("
allow_methods=("*"),
allow_headers=("*"),
)
# Initialize Whisper model - using "tiny" for faster CPU processing
print("Loading Whisper model (tiny)...")
model = whisper.load_model("tiny")
print("Whisper model loaded!")
# Database setup
def init_db():
conn = sqlite3.connect('meetings.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS meetings
(id INTEGER PRIMARY KEY AUTOINCREMENT,
filename TEXT,
transcript TEXT,
summary TEXT,
action_items TEXT,
created_at TIMESTAMP)''')
conn.commit()
conn.close()
init_db()
async def summarize_with_llm(transcript: str) -> dict:
"""Placeholder for LLM summarization logic"""
# This will be implemented in Step 2
return
@app.post("/upload")
async def upload_audio(file: UploadFile = File(...)):
file_path = f"temp_"
with open(file_path, "wb") as buffer:
content = await file.read()
buffer.write(content)
try:
# Step 1: Transcribe with Whisper
result = model.transcribe(file_path, fp16=False)
transcript = result("text")
# Step 2: Summarize (To be filled in Step 2)
summary_result = await summarize_with_llm(transcript)
# Step 3: Save to database
conn = sqlite3.connect('meetings.db')
c = conn.cursor()
c.execute(
"INSERT INTO meetings (filename, transcript, summary, action_items, created_at) VALUES (?, ?, ?, ?, ?)",
(file.filename, transcript, summary_result("summary"),
json.dumps(summary_result("action_items")), datetime.now())
)
conn.commit()
meeting_id = c.lastrowid
conn.close()
os.remove(file_path)
return err.message));
except Exception as e:
if os.path.exists(file_path):
os.remove(file_path)
raise HTTPException(status_code=500, detail=str(e))// Step 2: Integrating the free large language model
Now, let’s implement. summarize_with_llm() Function We will show two approaches:
Option A: Using GLM-4.7-Flash API (Cloud, Free)
from openai import OpenAI
async def summarize_with_llm(transcript: str) -> dict:
client = OpenAI(api_key="YOUR_FREE_ZHIPU_KEY", base_url="
response = client.chat.completions.create(
model="glm-4-flash",
messages=(
setError('Upload failed: ' + (err.response?.data?.detail ,
{"role": "user", "content": transcript}
),
response_format={"type": "json_object"}
)
return json.loads(response.choices(0).message.content)Option B: Using the native LFM2-2.6B-transcript (native, completely free)
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
async def summarize_with_llm_local(transcript):
model_name = "LiquidAI/LFM2-2.6B-Transcript"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
prompt = f"Analyze this transcript and provide a summary and action items:\n\n{transcript}"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=500)
return tokenizer.decode(outputs(0), skip_special_tokens=True)// Step 3: Building the React frontend
Create a simple React frontend to interact with our API. In a new terminal, create a React app:
npx create-react-app frontend
cd frontend
npm install axiosChange the content of src/App.js with:
import React, { useState } from 'react';
import axios from 'axios';
import './App.css';
function App() {
const (file, setFile) = useState(null);
const (uploading, setUploading) = useState(false);
const (result, setResult) = useState(null);
const (error, setError) = useState('');
const handleUpload = async () => {
if (!file) { setError('Please select a file'); return; }
setUploading(true);
const formData = new FormData();
formData.append('file', file);
try {
const response = await axios.post(' formData);
setResult(response.data);
} catch (err) {
setError('Upload failed: ' + (err.response?.data?.detail || err.message));
} finally { setUploading(false); }
};
return (
{result && (
Summary
{result.summary}
Action Items
{result.action_items.map((it, i) => - {it}
)}
)}
);
}
export default App;// Step 4: Run the application
- Start the backend: In the main directory with your virtual environment, run
uvicorn main:app --reload - Start the frontend: In a new terminal, in the frontend directory, run
npm start - open in your browser and upload a test audio file.
Dashboard interface showing summary results | Photo by author
# Application deployment for free
Once your app works locally, it’s time to deploy it to the world — still for free. Render Offers a generous free tier for web services. Push your code to the GitHub repository, create a new web service on Render, and use these settings:
- Environment: Python 3
- Create command:
pip install -r requirements.txt - Start the command:
uvicorn main:app --host 0.0.0.0 --port $PORT
Make a requirements.txt file:
fastapi
uvicorn
python-multipart
openai-whisper
transformers
torch
openaiNote: Whispers and transformers require significant disk space. If you hit the limits of the free tier, consider using the Cloud API for replication instead.
// Deploying the front-end to Vercel
Versailles The easiest way to deploy React apps is:
- Install Vercel CLI:
npm i -g vercel - In your frontend directory, run
vercel - Update your API URL.
App.jsto point to your render backend
// Exploring local deployment alternatives
If you want to avoid cloud hosting altogether, you can use both front-end and back-end on a local server using tools like ngrok To temporarily expose your local server.
# The result
We’ve just built a production-ready AI application using nothing but free tools. Let’s summarize what we got:
- Transcription: Used OpenAI’s Whisper (free, open source)
- Summary: Leveraged GLM-4.7-Flash or LFM2-2.6B (both completely free)
- Backend: Built with Fast API (Free)
- Frontend: Built with React (Free)
- Database: Used SQLite (free)
- Deployment: Deployed on Vercel and Render (free tiers)
- Development: Accelerate with free AI coding assistants like Codeium
The development landscape for free AI has never been more promising. Open source models now compete with commercial offerings. Native AI tools give us privacy and control. And generous free tiers from providers like Google and Zhipu AI let us prototype without financial risk.
Shatu Olomide A software engineer and technical writer with a knack for simplifying complex concepts and a keen eye for detail, passionate about leveraging modern technology to craft compelling narratives. You can also search on Shittu. Twitter.